文章詳情頁
python - 使用`zipfile`模塊在不解壓縮的情況下如何使用text模式讀取文本文件?
瀏覽:111日期:2022-06-28 10:12:34
問題描述
我使用的Python版本為3.5.2,嘗試用zipfile模塊的zipfile.ZipFile.open方法打開一個壓縮包中的文本文件時,即使使用了文檔中要求的rU參數,打開時仍然是以二進制數據格式打開的,百思不得其解。
代碼:
>>> import zipfile>>> zf = zipfile.ZipFile(’/Users/chiqingjun/Downloads/top-1m.csv.zip’)>>> zf.namelist()[’top-1m.csv’]>>> f = zf.open(zf.namelist()[0], mode=’rU’)>>> f<zipfile.ZipExtFile name=’top-1m.csv’ mode=’rU’ compress_type=deflate>>>> f.readline()b’1,google.comn’# 仍然是二進制數據
官方文檔(3.5.2版本):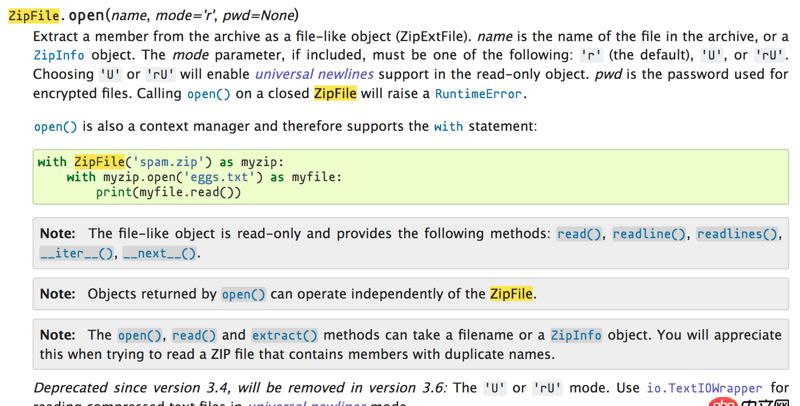
問題解答
回答1:其實最后輸出的二進制, 和zipfile無關, 是和py3.5有關, 你可以在輸出的結果解碼, 就能得到字符類型了
content = f.readline()print(content.decode(’utf8’))回答2:
文檔已經說了呀,rU是 通用換行符,并且將在3.6 移除此模式。
壓縮文件以二進制讀取字節內容是應該的,后面如何轉碼由程序員決定。
相關文章:
1. python - Win7調用flup報錯’module’ object has no attribute ’fromfd’2. 網頁爬蟲 - Python 爬蟲中如何處理驗證碼?3. mysql - 分庫分表、分區、讀寫分離 這些都是用在什么場景下 ,會帶來哪些效率或者其他方面的好處4. Python如何播放還存在StringIO中的MP3?5. javascript - 請教如何獲取百度貼吧新增的兩個加密參數6. mysql 一個sql 返回多個總數7. python - 我在使用pip install -r requirements.txt下載時,為什么部分能下載,部分不能下載8. mysql - 如何減少使用或者不用LEFT JOIN查詢?9. Python爬蟲如何爬取span和span中間的內容并分別存入字典里?10. python - 編碼問題求助
排行榜
 網公網安備
網公網安備