Python中如何將爬取到的數據循環存入到csv文件中?
問題描述
求大神指導 再此感激不盡!!!
我想要把輸出的結果存入到csv文件中
我的代碼如下:(Python 需要3.5版本的)
# coding:utf-8import requestsimport jsonimport timetime_unix = time.time()time_unix = str(time_unix).split(’.’)[0]headers = { ’Host’: ’sec.wedengta.com’, ’User-Agent’: ’Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.113 Safari/537.36’, ’Connection’: ’keep-alive’, ’Content-Language’: ’zh-CN,zh;q=0.8’, ’Accept’: ’application / json’, # ’Accept-Language’: ’ zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3’, ’X-Requested-With’: ’XMLHttpRequest’, ’Referer’: ’https://sec.wedengta.com/findPool.html?dt_from=web&title=%E8%85%BE%E8%AE%AF%E6%B6%A8%E5%81%9C%E6%9D%BF%E9%A2%84%E6%B5%8B%20-%20%E5%8E%86%E5%8F%B2%E6%8E%A8%E8%8D%90&id=99970_56&webviewType=userActivitesType&dt_page_type=11&timeStamp=1488801827765&barType=null&accessp=null’, ’Accept-Encoding’: ’gzip, deflate, br’ }url = ’https://sec.wedengta.com/getIntelliStock?action=IntelliSecPool&id=99970_56&_={0}’.format(time_unix)request = requests.get(url, headers=headers)temp = str(json.loads(request.text)).replace(’’, ’’)dic = eval(temp)content = dic[’content’]content = eval(content)vtDaySec = content[’vtDaySec’]for every in vtDaySec: for every_company in every[’vtSec’]:print(every[’sOptime’])print(every_company[’sChnName’])print(every_company[’sDtCode’][4:])print(’n’)
運行出來結果截圖: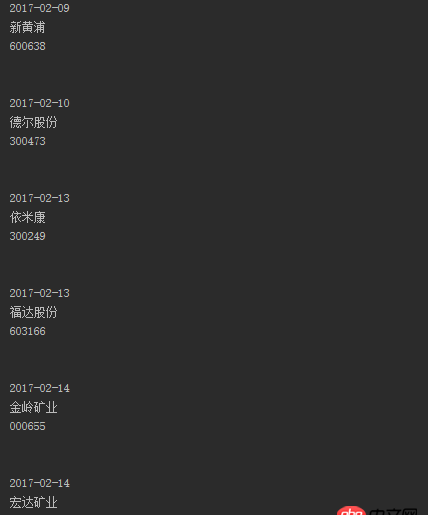
我想要的結果是:
問題解答
回答1:#coding=utf-8import requestsimport jsonimport timeimport csvimport codecsheaders = { ’User-Agent’: ’Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.113 Safari/537.36’}url = ’https://sec.wedengta.com/getIntelliStock?action=IntelliSecPool&id=99970_56&_={0}’.format(time.time())r = requests.get(url, headers=headers)result = json.loads(r.text)rows = []for every in json.loads(result[’content’])[’vtDaySec’]: for company in every[’vtSec’]:row = ( every[’sOptime’].encode(’utf-8’), company[’sChnName’].encode(’utf-8’), company[’sDtCode’][4:].encode(’utf-8’))rows.append(row)with codecs.open(’company.csv’, ’wb’) as f: f.write(codecs.BOM_UTF8) writer = csv.writer(f) writer.writerow([’date’, ’stk_name’, ’stk_num’]) writer.writerows(rows)回答2:
csv = open(’data.csv’, ’w’)for every in vtDaySec: for every_company in every[’vtSec’]:csv.write(’,’.join([every[’sOptime’], every_company[’sChnName’], every_company[’sDtCode’][4:]]) + ’n’)csv.close()
相關文章:
1. mysql - 如何減少使用或者不用LEFT JOIN查詢?2. 視頻文件不能播放,怎么辦?3. mysql - jdbc的問題4. python - 我在使用pip install -r requirements.txt下載時,為什么部分能下載,部分不能下載5. html5 - H5做的手機分享頁微信更新后,分享出去不再默認顯示第一個圖 作為縮略圖6. python - 編碼問題求助7. linux - python 抓取公眾號文章遇到驗證問題8. mysql - 分庫分表、分區、讀寫分離 這些都是用在什么場景下 ,會帶來哪些效率或者其他方面的好處9. node.js - nodejs開發中常用的連接mysql的庫10. 網頁爬蟲 - python 爬取網站 并解析非json內容
 網公網安備
網公網安備