Python實現一個論文下載器的過程
在科研學習的過程中,我們難免需要查詢相關的文獻資料,而想必很多小伙伴都知道SCI-HUB,此乃一大神器,它可以幫助我們搜索相關論文并下載其原文。可以說,SCI-HUB造福了眾多科研人員,用起來也是“美滋滋”。

然而,當師姐告訴我:“xx,可以幫我下載幾篇文獻嘛?”。樂心助人的我自當是滿口答應了,心想:“這種小事就交給我叭~”
于是乎,我收到了一個excel文檔,66篇論文的列表安靜地趟在里面(此刻心中碎碎念:“這尼瑪,是幾篇嘛...”)。我粗略算了一下,復制、粘貼、下載,一套流程走下來,每篇論文少說也得30秒,66篇的話....啊,這不能忍!
很顯然,一篇一篇的下載,不是我的風格所以,我決定寫一個論文下載器助我前行。
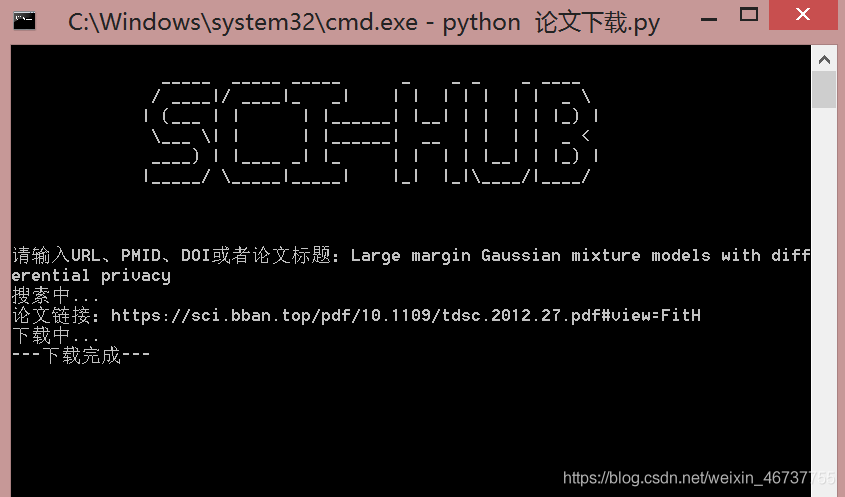
代碼分析的詳細思路跟以往依舊如此雷同,逃不過的還是:抓包分析->模擬請求->代碼整合。由于一會兒kimol君還得去搬磚,今天就不詳細展開了。
1. 搜索論文通過論文的URL、PMID、DOI號或者論文標題等搜索到對應的論文,并通過bs4庫找出PDF原文的鏈接地址,代碼如下:
def search_article(artName): ’’’ 搜索論文 --------------- 輸入:論文名 --------------- 輸出:搜索結果(如果沒有返回'',否則返回PDF鏈接) ’’’ url = ’https://www.sci-hub.ren/’ headers = {’User-Agent’:’Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:84.0) Gecko/20100101 Firefox/84.0’, ’Accept’:’text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8’, ’Accept-Language’:’zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2’, ’Accept-Encoding’:’gzip, deflate, br’, ’Content-Type’:’application/x-www-form-urlencoded’, ’Content-Length’:’123’, ’Origin’:’https://www.sci-hub.ren’, ’Connection’:’keep-alive’, ’Upgrade-Insecure-Requests’:’1’} data = {’sci-hub-plugin-check’:’’, ’request’:artName} res = requests.post(url, headers=headers, data=data) html = res.text soup = BeautifulSoup(html, ’html.parser’) iframe = soup.find(id=’pdf’) if iframe == None: # 未找到相應文章 return ’’ else: downUrl = iframe[’src’] if ’http’ not in downUrl: downUrl = ’https:’+downUrl return downUrl2. 下載論文
得到了論文的鏈接地址之后,只需要通過requests發送一個請求,即可將其下載:
def download_article(downUrl): ’’’ 根據論文鏈接下載文章 ---------------------- 輸入:論文鏈接 ---------------------- 輸出:PDF文件二進制 ’’’ headers = {’User-Agent’:’Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:84.0) Gecko/20100101 Firefox/84.0’, ’Accept’:’text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8’, ’Accept-Language’:’zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2’, ’Accept-Encoding’:’gzip, deflate, br’, ’Connection’:’keep-alive’, ’Upgrade-Insecure-Requests’:’1’} res = requests.get(downUrl, headers=headers) return res.content二、完整代碼
將上述兩個函數整合之后,我的完整代碼如下:
# -*- coding: utf-8 -*-'''Created on Tue Jan 5 16:32:22 2021@author: kimol_love'''import osimport timeimport requestsfrom bs4 import BeautifulSoup def search_article(artName): ’’’ 搜索論文 --------------- 輸入:論文名 --------------- 輸出:搜索結果(如果沒有返回'',否則返回PDF鏈接) ’’’ url = ’https://www.sci-hub.ren/’ headers = {’User-Agent’:’Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:84.0) Gecko/20100101 Firefox/84.0’, ’Accept’:’text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8’, ’Accept-Language’:’zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2’, ’Accept-Encoding’:’gzip, deflate, br’, ’Content-Type’:’application/x-www-form-urlencoded’, ’Content-Length’:’123’, ’Origin’:’https://www.sci-hub.ren’, ’Connection’:’keep-alive’, ’Upgrade-Insecure-Requests’:’1’} data = {’sci-hub-plugin-check’:’’, ’request’:artName} res = requests.post(url, headers=headers, data=data) html = res.text soup = BeautifulSoup(html, ’html.parser’) iframe = soup.find(id=’pdf’) if iframe == None: # 未找到相應文章 return ’’ else: downUrl = iframe[’src’] if ’http’ not in downUrl: downUrl = ’https:’+downUrl return downUrl def download_article(downUrl): ’’’ 根據論文鏈接下載文章 ---------------------- 輸入:論文鏈接 ---------------------- 輸出:PDF文件二進制 ’’’ headers = {’User-Agent’:’Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:84.0) Gecko/20100101 Firefox/84.0’, ’Accept’:’text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8’, ’Accept-Language’:’zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2’, ’Accept-Encoding’:’gzip, deflate, br’, ’Connection’:’keep-alive’, ’Upgrade-Insecure-Requests’:’1’} res = requests.get(downUrl, headers=headers) return res.content def welcome(): ’’’ 歡迎界面 ’’’ os.system(’cls’) title = ’’’ _____ _____ _____ _ _ _ _ ____ / ____|/ ____|_ _| | | | | | | | _ | (___ | | | |______| |__| | | | | |_) | ___ | | | |______| __ | | | | _ < ____) | |____ _| |_ | | | | |__| | |_) | |_____/ _____|_____| |_| |_|____/|____/ ’’’ print(title) if __name__ == ’__main__’: while True: welcome() request = input(’請輸入URL、PMID、DOI或者論文標題:’) print(’搜索中...’) downUrl = search_article(request) if downUrl == ’’: print(’未找到相關論文,請重新搜索!’) else: print(’論文鏈接:%s’%downUrl) print(’下載中...’) pdf = download_article(downUrl) with open(’%s.pdf’%request, ’wb’) as f: f.write(pdf) print(’---下載完成---’) time.sleep(0.8)
不出所料,代碼一跑,我便輕松完成了師姐交給我的任務,不香嘛?
到此這篇關于Python實現一個論文下載器的過程的文章就介紹到這了,更多相關python論文下載器內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:
 網公網安備
網公網安備