Python 微信公眾號文章爬取的示例代碼
一.思路
我們通過網(wǎng)頁版的微信公眾平臺的圖文消息中的超鏈接獲取到我們需要的接口
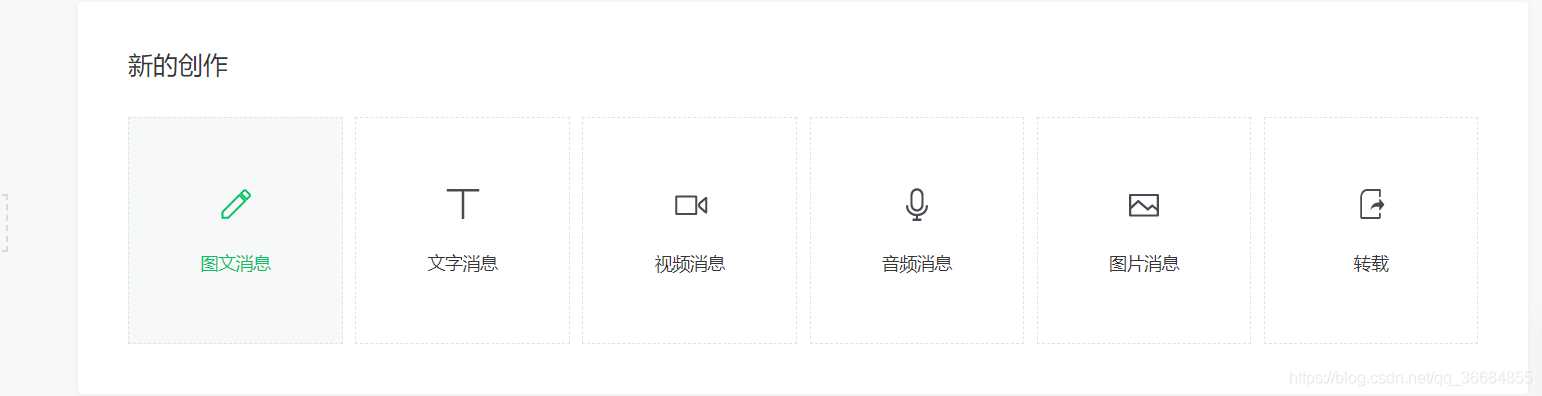

從接口中我們可以得到對應(yīng)的微信公眾號和對應(yīng)的所有微信公眾號文章。
二.接口分析
獲取微信公眾號的接口:https://mp.weixin.qq.com/cgi-bin/searchbiz?參數(shù):action=search_bizbegin=0count=5query=公眾號名稱token=每個賬號對應(yīng)的token值lang=zh_CNf=jsonajax=1請求方式:GET所以這個接口中我們只需要得到token即可,而query則是你需要搜索的公眾號,token則可以通過登錄后的網(wǎng)頁鏈接獲取得到。
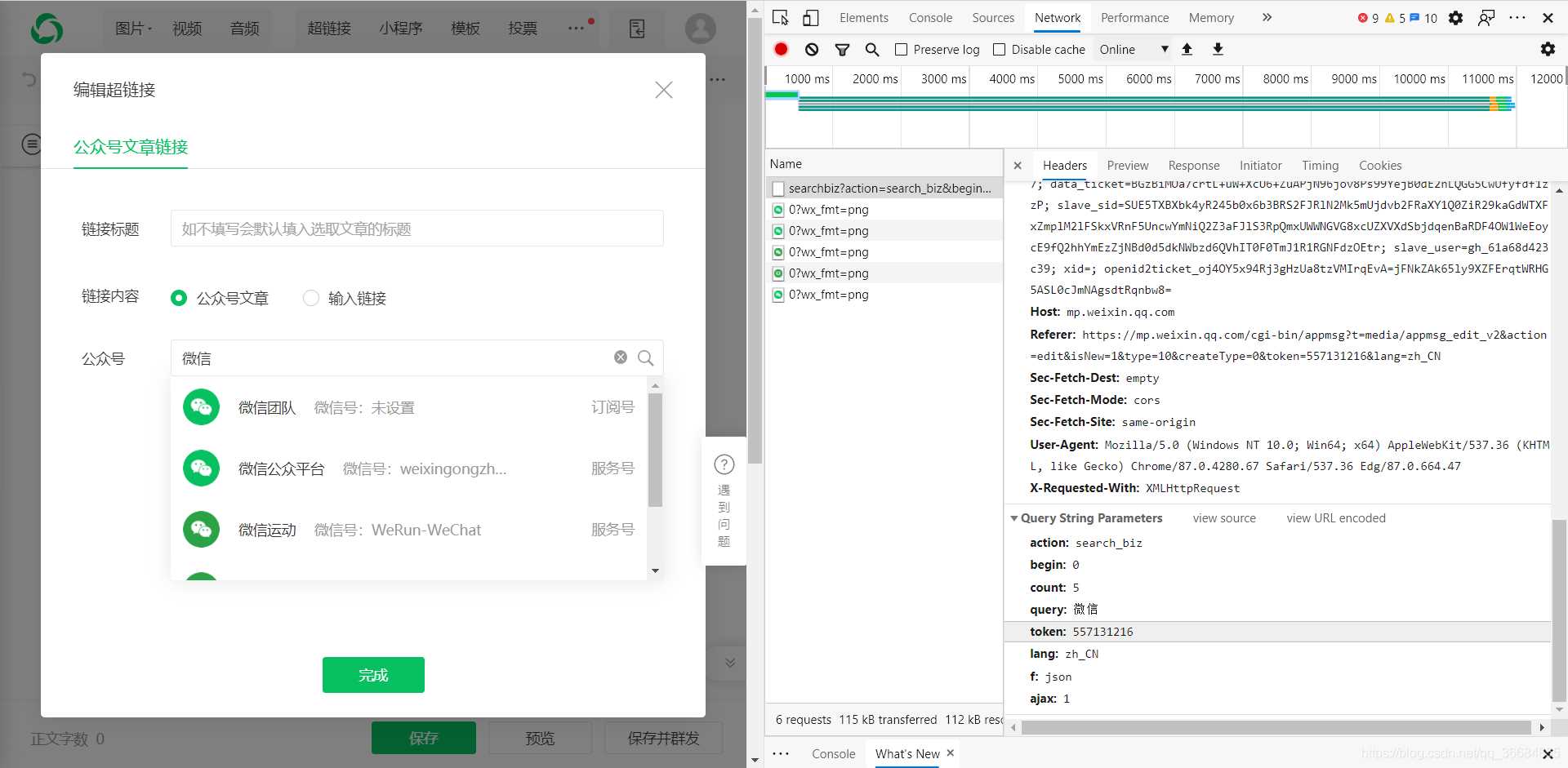
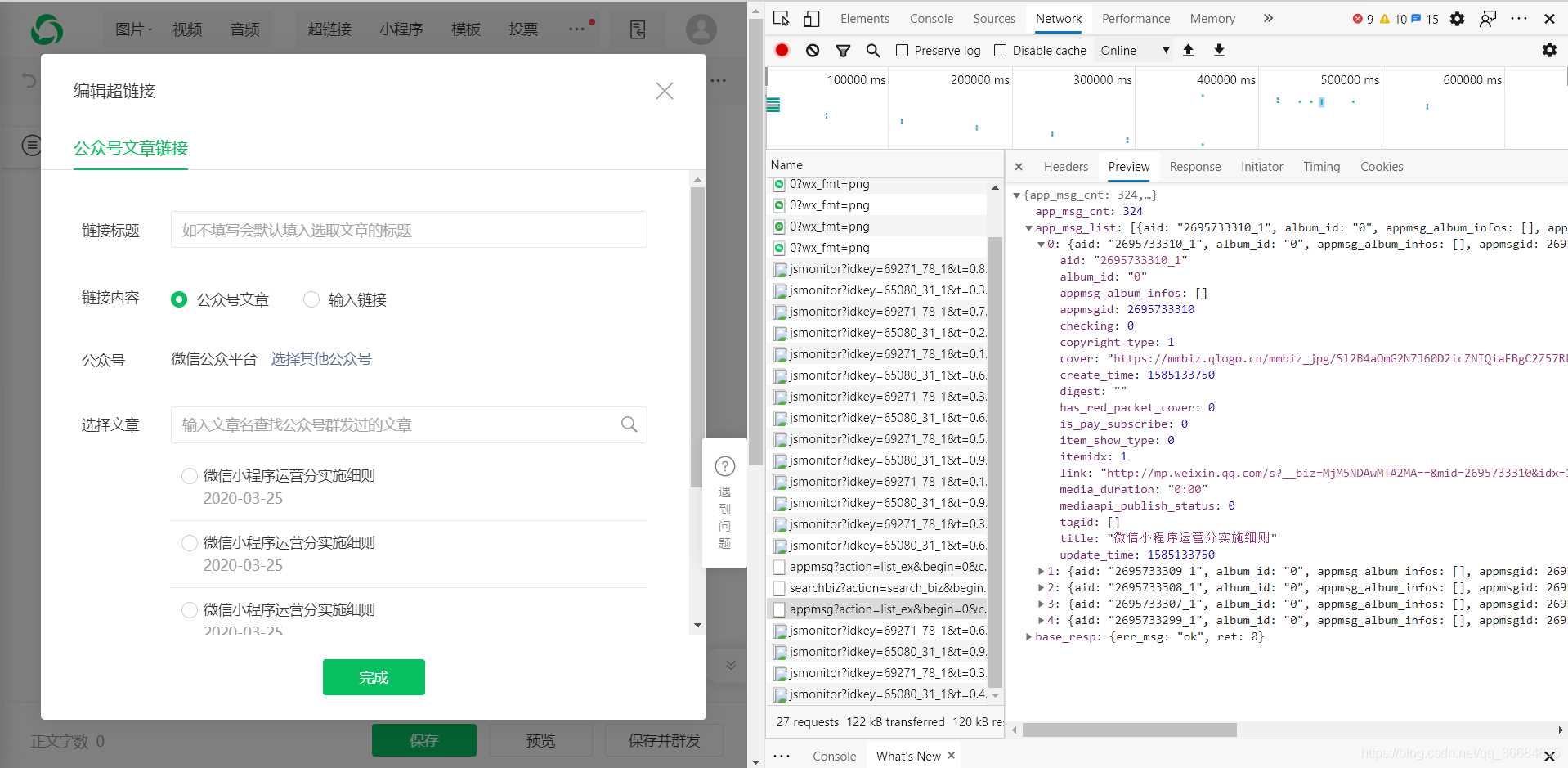
獲取對應(yīng)公眾號的文章的接口:https://mp.weixin.qq.com/cgi-bin/appmsg?參數(shù):action=list_exbegin=0count=5fakeid=MjM5NDAwMTA2MA==type=9query=token=557131216lang=zh_CNf=jsonajax=1請求方式:GET在這個接口中我們需要獲取的值有上一步的token以及fakeid,而這個fakeid則在第一個接口中可以獲取得到。從而我們就可以拿到微信公眾號文章的數(shù)據(jù)了。
三.實現(xiàn)
第一步:
首先我們需要通過selenium模擬登錄,然后獲取到cookie和對應(yīng)的token
def weChat_login(user, password): post = {} browser = webdriver.Chrome() browser.get(’https://mp.weixin.qq.com/’) sleep(3) browser.delete_all_cookies() sleep(2) # 點擊切換到賬號密碼輸入 browser.find_element_by_xpath('//a[@class=’login__type__container__select-type’]').click() sleep(2) # 模擬用戶點擊 input_user = browser.find_element_by_xpath('//input[@name=’account’]') input_user.send_keys(user) input_password = browser.find_element_by_xpath('//input[@name=’password’]') input_password.send_keys(password) sleep(2) # 點擊登錄 browser.find_element_by_xpath('//a[@class=’btn_login’]').click() sleep(2) # 微信登錄驗證 print(’請掃描二維碼’) sleep(20) # 刷新當(dāng)前網(wǎng)頁 browser.get(’https://mp.weixin.qq.com/’) sleep(5) # 獲取當(dāng)前網(wǎng)頁鏈接 url = browser.current_url # 獲取當(dāng)前cookie cookies = browser.get_cookies() for item in cookies: post[item[’name’]] = item[’value’] # 轉(zhuǎn)換為字符串 cookie_str = json.dumps(post) # 存儲到本地 with open(’cookie.txt’, ’w+’, encoding=’utf-8’) as f: f.write(cookie_str) print(’cookie保存到本地成功’) # 對當(dāng)前網(wǎng)頁鏈接進行切片,獲取到token paramList = url.strip().split(’?’)[1].split(’&’) # 定義一個字典存儲數(shù)據(jù) paramdict = {} for item in paramList: paramdict[item.split(’=’)[0]] = item.split(’=’)[1] # 返回token return paramdict[’token’]
定義了一個登錄方法,里面的參數(shù)為登錄的賬號和密碼,然后定義了一個字典用來存儲cookie的值。通過模擬用戶輸入對應(yīng)的賬號密碼并且點擊登錄,然后會出現(xiàn)一個掃碼驗證,用登錄的微信去掃碼即可。刷新當(dāng)前網(wǎng)頁后,獲取當(dāng)前cookie以及token然后返回。
第二步:
1.請求獲取對應(yīng)公眾號接口,取到我們需要的fakeid
url = ’https://mp.weixin.qq.com’ headers = { ’HOST’: ’mp.weixin.qq.com’, ’User-Agent’: ’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63’ } with open(’cookie.txt’, ’r’, encoding=’utf-8’) as f: cookie = f.read() cookies = json.loads(cookie) resp = requests.get(url=url, headers=headers, cookies=cookies) search_url = ’https://mp.weixin.qq.com/cgi-bin/searchbiz?’ params = { ’action’: ’search_biz’, ’begin’: ’0’, ’count’: ’5’, ’query’: ’搜索的公眾號名稱’, ’token’: token, ’lang’: ’zh_CN’, ’f’: ’json’, ’ajax’: ’1’ } search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
將我們獲取到的token和cookie傳進來,然后通過requests.get請求,獲得返回的微信公眾號的json數(shù)據(jù)
lists = search_resp.json().get(’list’)[0]
通過上面的代碼即可獲取到對應(yīng)的公眾號數(shù)據(jù)
fakeid = lists.get(’fakeid’)
通過上面的代碼就可以得到對應(yīng)的fakeid
2.請求獲取微信公眾號文章接口,取到我們需要的文章數(shù)據(jù)
appmsg_url = ’https://mp.weixin.qq.com/cgi-bin/appmsg?’ params_data = { ’action’: ’list_ex’, ’begin’: ’0’, ’count’: ’5’, ’fakeid’: fakeid, ’type’: ’9’, ’query’: ’’, ’token’: token, ’lang’: ’zh_CN’, ’f’: ’json’, ’ajax’: ’1’ } appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我們傳入fakeid和token然后還是調(diào)用requests.get請求接口,獲得返回的json數(shù)據(jù)。我們就實現(xiàn)了對微信公眾號文章的爬取。
四.總結(jié)
通過對微信公眾號文章的爬取,需要掌握selenium和requests的用法,以及如何獲取到請求接口。但是需要注意的是當(dāng)我們循環(huán)獲取文章時,一定要設(shè)置延遲時間,不然賬號很容易被封禁,從而得不到返回的數(shù)據(jù)。
到此這篇關(guān)于Python 微信公眾號文章爬取的示例代碼的文章就介紹到這了,更多相關(guān)Python 微信公眾號文章爬取內(nèi)容請搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備