文章詳情頁
Python Selenium實現無可視化界面過程解析
瀏覽:10日期:2022-07-13 10:04:48
無可視化界面的意義
有時候我們爬取網頁數據,并不希望看其中的過程,只想看到最后的數據結果就可以了,這時候,***面就很有必要了!
代碼如下
from selenium import webdriverfrom time import sleep#實現無可視化界面from selenium.webdriver.chrome.options import Options#實現規避檢測from selenium.webdriver import ChromeOptions#實現無可視化界面的操作chrome_options = Options()chrome_options.add_argument(’--headless’)chrome_options.add_argument(’--disable-gpu’)#實現規避檢測option = ChromeOptions()option.add_experimental_option(’excludeSwitches’, [’enable-automation’])#如何實現讓selenium規避被檢測到的風險bro = webdriver.Chrome(executable_path=’./chromedriver’,chrome_options=chrome_options,options=option)#無可視化界面(無頭瀏覽器) phantomJsbro.get(’https://www.baidu.com’)print(bro.page_source)sleep(2)bro.quit()
運行效果:
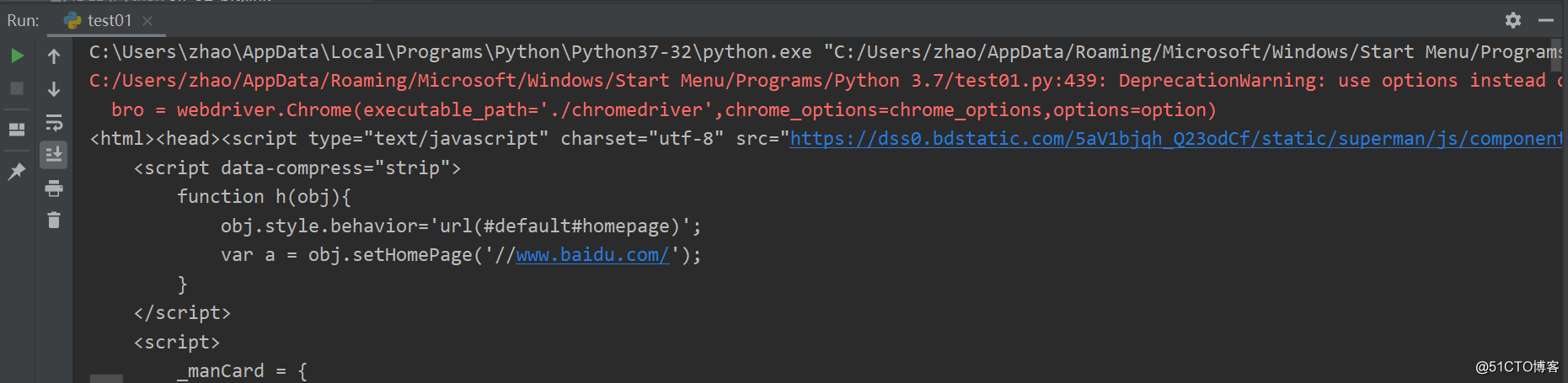
打印出網頁代碼,證明爬取網站信息成功
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持好吧啦網。
相關文章:
1. python利用os模塊編寫文件復制功能——copy()函數用法2. php測試程序運行速度和頁面執行速度的代碼3. php網絡安全中命令執行漏洞的產生及本質探究4. 三個不常見的 HTML5 實用新特性簡介5. 無線標記語言(WML)基礎之WMLScript 基礎第1/2頁6. ajax請求添加自定義header參數代碼7. Python使用jupyter notebook查看ipynb文件過程解析8. 解決Python 進程池Pool中一些坑9. 解決python腳本中error: unrecognized arguments: True錯誤10. IntelliJ IDEA創建普通的Java 項目及創建 Java 文件并運行的教程
排行榜

 網公網安備
網公網安備