Python實現爬取網頁中動態加載的數據
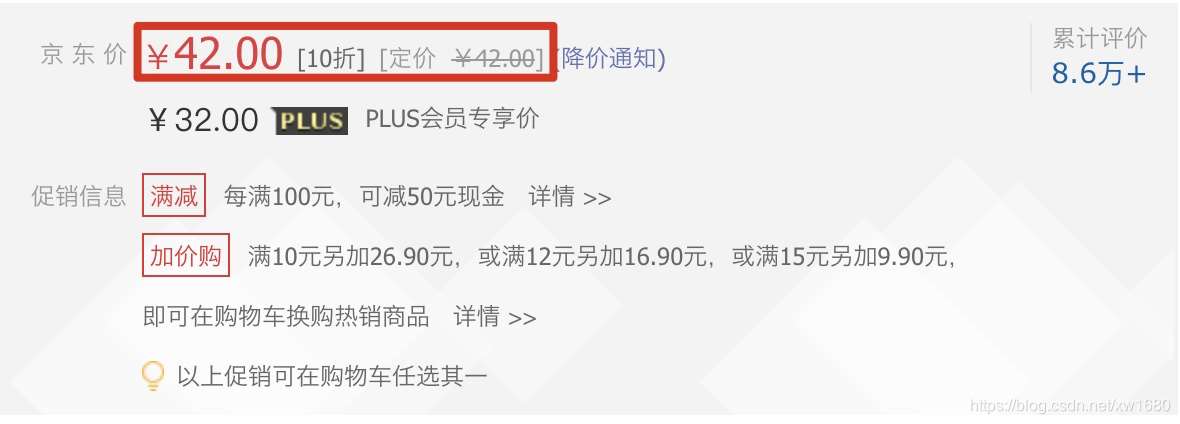
在使用python爬蟲技術采集數據信息時,經常會遇到在返回的網頁信息中,無法抓取動態加載的可用數據。例如,獲取某網頁中,商品價格時就會出現此類現象。如下圖所示。本文將實現爬取網頁中類似的動態加載的數據。
1. 那么什么是動態加載的數據?
我們通過requests模塊進行數據爬取無法每次都是可見即可得,有些數據是通過非瀏覽器地址欄中的url請求得到的。而是通過其他請求請求到的數據,那么這些通過其他請求請求到的數據就是動態加載的數據。(猜測有可能是js代碼當咱們訪問此頁面時就會發送得get請求,到其他url中獲取數據)
2. 如何檢測網頁中是否存在動態加載得數據?
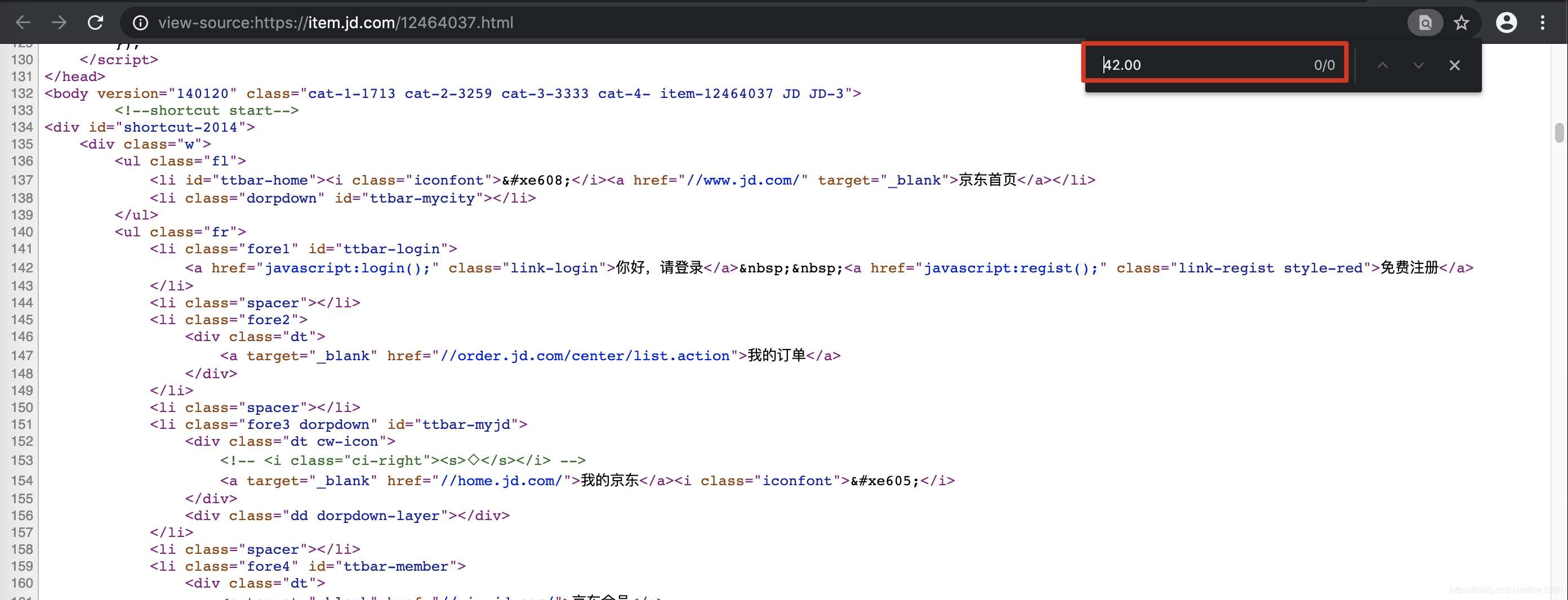
在當前頁面中打開抓包工具,捕獲到地址欄中的url對應的數據包,在該數據包的response選項卡搜索我們想要爬取的數據,如果搜索到了結果則表示數據不是動態加載的,否則表示數據為動態加載的。如圖所示:

或者鼠標右鍵單擊要爬取的頁面顯示網頁源代碼搜索我們想要爬取的數據,如果搜索到了結果則表示數據不是動態加載的,否則表示數據為動態加載的。如圖所示:
3. 如果數據為動態加載,那么我們如何捕獲到動態加載的數據?
在實現爬取動態加載的數據信息時,首先需要在瀏覽器的網絡監視器中根據動態加載的技術選擇網絡請求的類型,然后通過逐個篩選的方式查詢預覽信息中的關鍵數據,并獲取對應的請求地址,最后進行信息的解析工作即可。具體步驟如下:
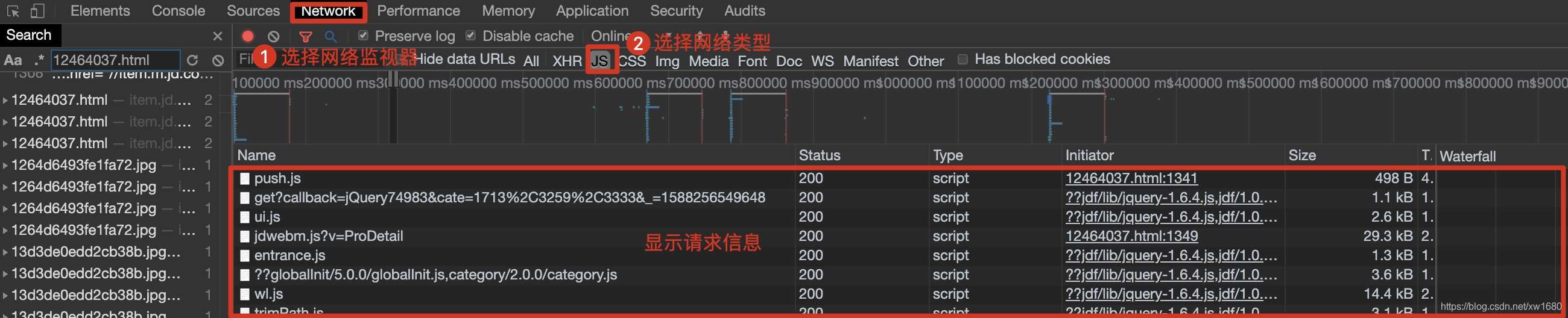
在瀏覽器中快捷鍵F12打開開發者工具,然后選擇Network(網絡監視器)并在網絡類型中選擇JS,再按快捷鍵F5刷新,如下圖所示。
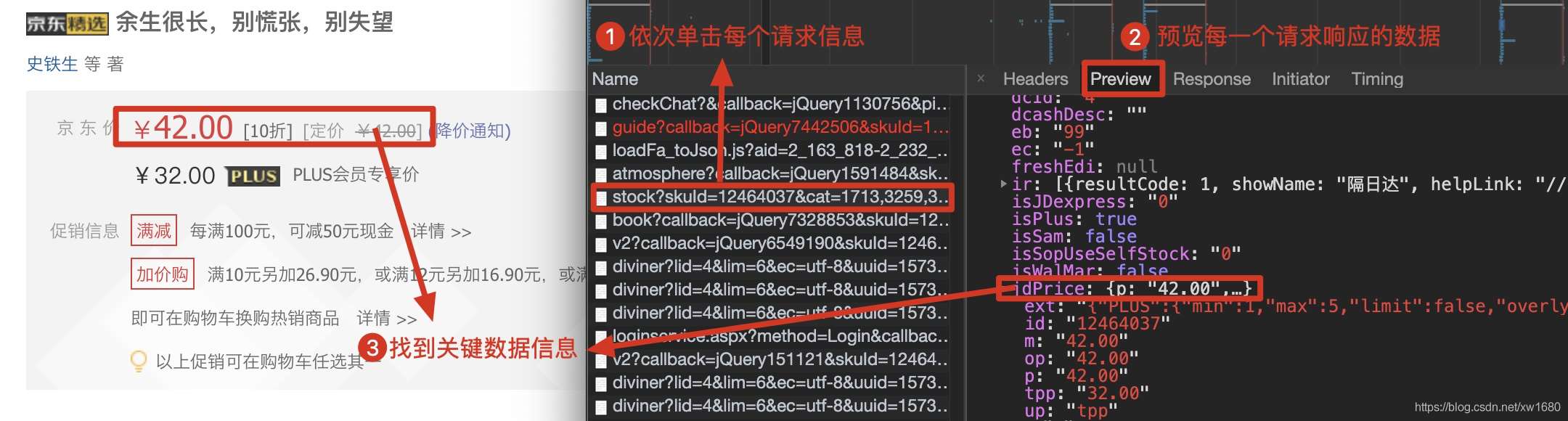
在請求信息的列表中,依次單擊每個請求信息,然后在對應的Preview(請求結果預覽)中核對是否為需要獲取的動態加載數據,如下圖所示。
動態加載的數據信息核對完成后,單擊Headers獲取當前的網絡請求地址以及所需參數,如下圖所示。
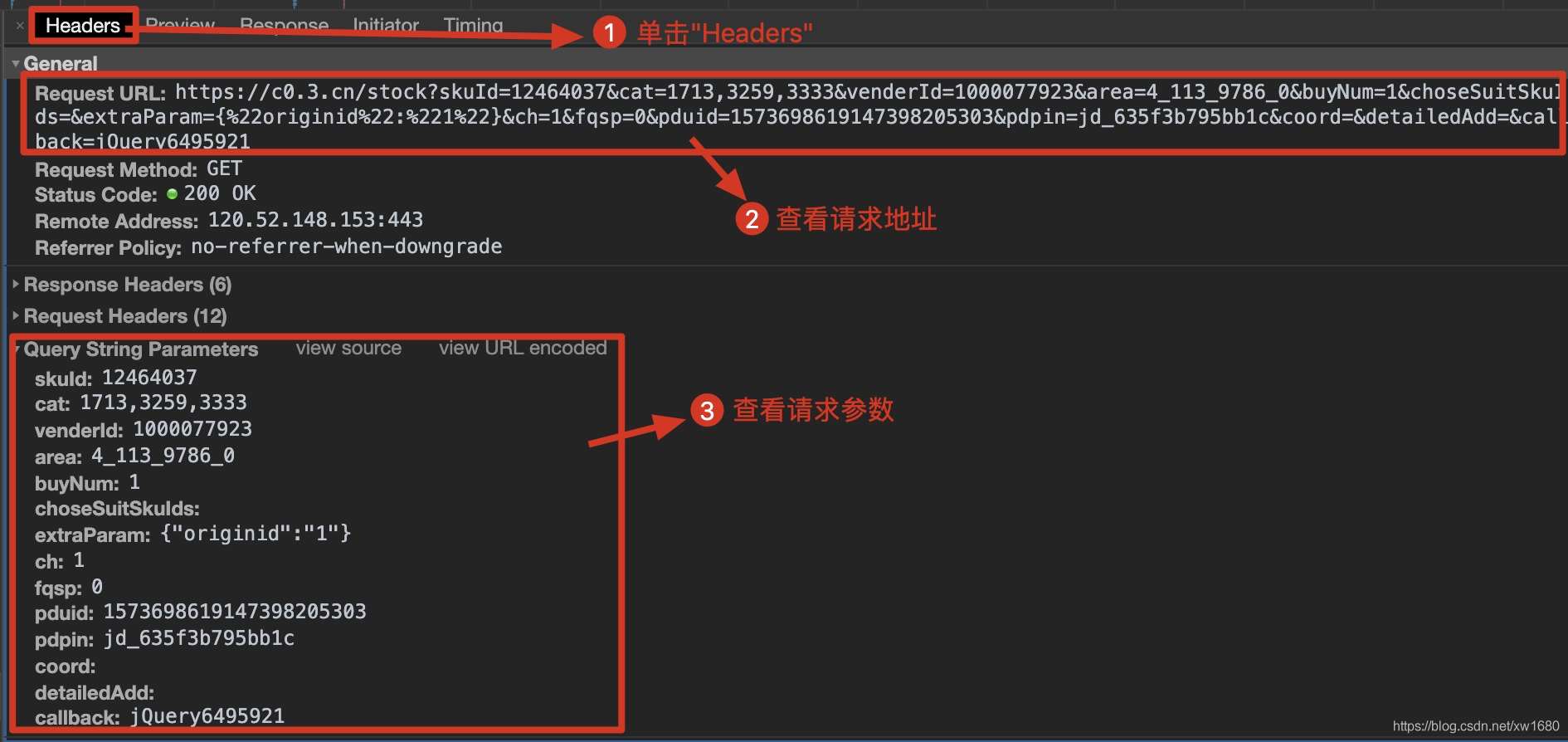
根據以上步驟獲取到的請求地址,發送網絡請求并從返回的信息中提取商品價格信息。筆者在代碼中使用到了反序列化,關于json序列化和反序列化可以點擊 此處 進行學習,代碼如下:
import requestsimport json# 獲取商品價格的請求地址url = 'https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area' '=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&' 'pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921'jQuery_id = url.split('=')[-1] + '('# 頭部信息headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) ' 'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36'}# 發送網絡請求response = requests.get(url, headers=headers)if response.status_code == 200: goods_dict = json.loads(response.text.replace(jQuery_id, '')[:-1]) # 反序列化 print(f'當前售價為: {goods_dict[’stock’][’jdPrice’][’op’]}') print(f'定價為: {goods_dict[’stock’][’jdPrice’][’m’]}') print(f'會員價為: {goods_dict[’stock’][’jdPrice’][’tpp’]}')else: print('請求失敗!')
筆者在寫博文的時候,價格發生了變化,運行結果如下圖所示:
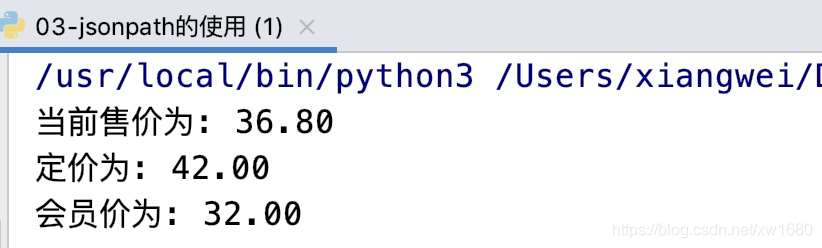
注意:爬取動態加載數據信息時,需要根據不同的網頁使用不同的方式進行數據的提取。如果在運行源碼時出現了錯誤,請根據操作步驟獲取新的請求地址即可。
到此這篇關于Python實現爬取網頁中動態加載的數據的文章就介紹到這了,更多相關Python 爬取網頁動態數據內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:
 網公網安備
網公網安備