Python pandas 列轉行操作詳解(類似hive中explode方法)
最近在工作上用到Python的pandas庫來處理excel文件,遇到列轉行的問題。找了一番資料后成功了,記錄一下。
1. 如果需要爆炸的只有一列:
df=pd.DataFrame({’A’:[1,2],’B’:[[1,2],[1,2]]})dfOut[1]: A B0 1 [1, 2]1 2 [1, 2]
如果要爆炸B這一列,可以直接用explode方法(前提是你的pandas的版本要高于或等于0.25)
df.explode(’B’) A B 0 1 1 1 1 2 2 2 1 3 2 2
2. 如果需要爆炸的有2列及以上
df=pd.DataFrame({’A’:[1,2],’B’:[[1,2],[3,4]],’C’:[[1,2],[3,4]]})dfOut[592]: A B C0 1 [1, 2] [1, 2]1 2 [3, 4] [3, 4]
則可以用寫一個方法,如下代碼:
def unnesting(df, explode): idx = df.index.repeat(df[explode[0]].str.len()) df1 = pd.concat([ pd.DataFrame({x: np.concatenate(df[x].values)}) for x in explode], axis=1) df1.index = idx return df1.join(df.drop(explode, 1), how=’left’) unnesting(df,[’B’,’C’])Out[2]: B C A0 1 1 10 2 2 11 3 3 21 4 4 2
補充知識:pandas:一列分解成多列 series.str.split(’,’,expand=True);pyspark 一列分解成多列
源shuju
question_id id0 17576 70391,703941 17576 70391,70392,70393,703942 17576 70391,703923 40430 155032,155033,1550344 40430 155032,155033,155034,1550355 40430 155033,155034,1550356 40430 155032,1550357 40430 155034,1550358 40430 155032,1550349 40430 155032,155034,15503510 40430 155033,15503411 40430 155032,15503312 40430 155033,15503513 40430 155032,155033,155035
pandas solution
df.join(df[’id’].str.split(’,’,expand=True)
result
0 1 2 30 70391 70394 None None1 70391 70392 70393 703942 70391 70392 None None3 155032 155033 155034 None4 155032 155033 155034 1550355 155033 155034 155035 None6 155032 155035 None None7 155034 155035 None None8 155032 155034 None None9 155032 155034 155035 None10 155033 155034 None None11 155032 155033 None None12 155033 155035 None None13 155032 155033 155035 None
#注意expand=True
df.join(df[’id’].str.split(’,’,expand=True))
question_id id 0 1 2 30 17576 70391,70394 70391 70394 None None1 17576 70391,70392,70393,70394 70391 70392 70393 703942 17576 70391,70392 70391 70392 None None3 40430 155032,155033,155034 155032 155033 155034 None4 40430 155032,155033,155034,155035 155032 155033 155034 1550355 40430 155033,155034,155035 155033 155034 155035 None6 40430 155032,155035 155032 155035 None None7 40430 155034,155035 155034 155035 None None8 40430 155032,155034 155032 155034 None None9 40430 155032,155034,155035 155032 155034 155035 None10 40430 155033,155034 155033 155034 None None11 40430 155032,155033 155032 155033 None None12 40430 155033,155035 155033 155035 None None13 40430 155032,155033,155035 155032 155033 155035 None
pyspark solution tdf=df.select(F.split(df.id,’,’).alias(’ss’),’question_id’,’count_num’) tdf.sort(’question_id’).show() res=tdf.select(F.explode(tdf.ss).alias(’new’),’question_id’,’count_num’)res.sort(’question_id’).show()res.groupBy(’question_id’,’new’).sum().sort(’question_id’).show()
result
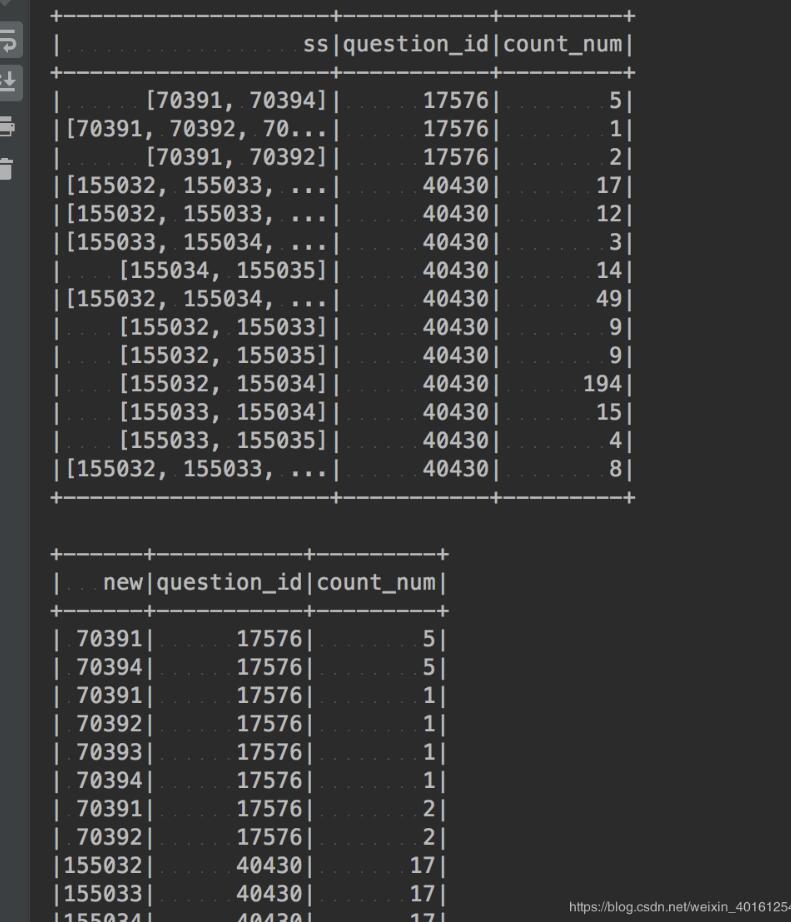
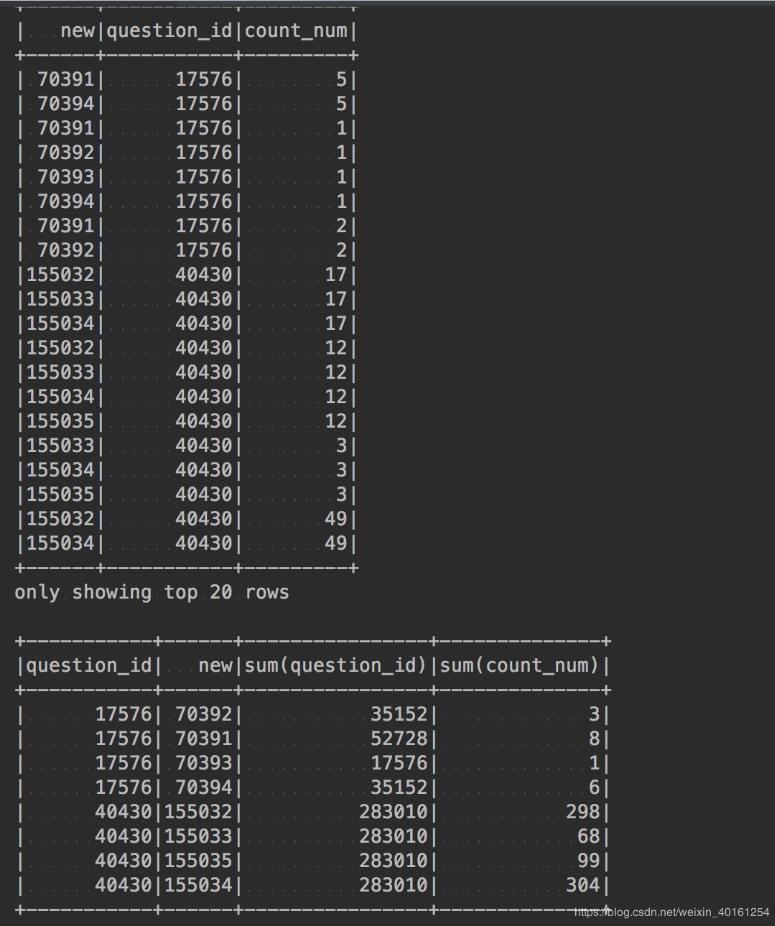
以上這篇Python pandas 列轉行操作詳解(類似hive中explode方法)就是小編分享給大家的全部內容了,希望能給大家一個參考,也希望大家多多支持好吧啦網。
相關文章:

 網公網安備
網公網安備