JAVA實現DOC轉PDF的示例代碼
Word作為目前主流的文本編輯軟件之一,功能十分強大,應用人群廣,但是它也存在一些問題。像是Word文件在不同軟件或操作平臺之間傳輸的時候,時不時會出現各種格式的“變化”,也會有點“不穩定”,例如內容和格式經常容易篡動。
相較于Word,pdf格式文件顯然優秀不少。雖然在內容編輯和修改方面表現不佳,但pdf格式文件在不同平臺和軟件上的穩定性表現著實出色。日常辦公中,越來越多的會選擇將編輯好的Word文件轉換成Pdf格式文件,然后再分享給第三方瀏覽。
如果只是1個Word文件轉換成Pdf文件,簡直so easy;10個Word文件轉換成pdf文件,雖煩躁,但能忍;如果是將1000個word文件轉換成pdf文件呢?這會估計一股無名之火直沖天靈蓋,立馬想摔電腦的沖動都有了。
但對于程序猿來說,操作起來顯然會容易很多,正好接到一個任務,索性就來和大家分享一下:將docx轉成PDF文檔,還要以代碼的方式實現批量操作。先后參考了Apache poi java庫以及docx4j組件,于是選擇以docx4j組件來進行文檔操作。
第一批次的文檔共90篇:

以下開始實現docx4j的文檔轉PDF功能:
一、下載依賴docx4j所有的依賴jar包使用marven去處理還是蠻簡潔的:
<dependency><groupId>org.docx4j</groupId><artifactId>docx4j-JAXB-Internal</artifactId><version>8.2.4</version></dependency><dependency><groupId>org.docx4j</groupId><artifactId>docx4j-export-fo</artifactId><version>8.2.4</version></dependency>
就兩個,短暫等待下載依賴之后發現,docx4j的依賴jar包還是挺多的:
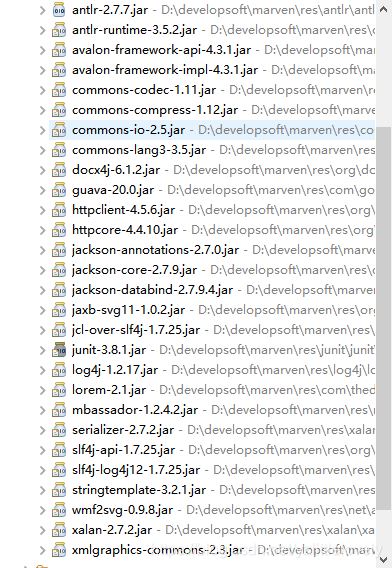
手動開始敲代碼吧。
二、代碼實現package com.convert.test;import java.io.File;import java.io.FileNotFoundException;import java.io.FileOutputStream;import org.docx4j.Docx4J;import org.docx4j.fonts.IdentityPlusMapper;import org.docx4j.fonts.Mapper;import org.docx4j.fonts.PhysicalFonts;import org.docx4j.openpackaging.exceptions.Docx4JException;import org.docx4j.openpackaging.packages.WordprocessingMLPackage;public class ConvertTest {public static void main(String[] args) {word2pdf('D:tran2.doc', 'D:tran2.pdf');}public static void word2pdf(String source, String target) {try { WordprocessingMLPackage pkg = Docx4J.load(new File(source)); Mapper fontMapper = new IdentityPlusMapper(); fontMapper.put('隸書', PhysicalFonts.get('LiSu')); fontMapper.put('宋體', PhysicalFonts.get('SimSun')); fontMapper.put('微軟雅黑', PhysicalFonts.get('Microsoft Yahei')); fontMapper.put('黑體', PhysicalFonts.get('SimHei')); fontMapper.put('楷體', PhysicalFonts.get('KaiTi')); fontMapper.put('新宋體', PhysicalFonts.get('NSimSun')); fontMapper.put('華文行楷', PhysicalFonts.get('STXingkai')); fontMapper.put('華文仿宋', PhysicalFonts.get('STFangsong')); fontMapper.put('仿宋', PhysicalFonts.get('FangSong')); fontMapper.put('幼圓', PhysicalFonts.get('YouYuan')); fontMapper.put('華文宋體', PhysicalFonts.get('STSong')); fontMapper.put('華文中宋', PhysicalFonts.get('STZhongsong')); fontMapper.put('等線', PhysicalFonts.get('SimSun')); fontMapper.put('等線 Light', PhysicalFonts.get('SimSun')); fontMapper.put('華文琥珀', PhysicalFonts.get('STHupo')); fontMapper.put('華文隸書', PhysicalFonts.get('STLiti')); fontMapper.put('華文新魏', PhysicalFonts.get('STXinwei')); fontMapper.put('華文彩云', PhysicalFonts.get('STCaiyun')); fontMapper.put('方正姚體', PhysicalFonts.get('FZYaoti')); fontMapper.put('方正舒體', PhysicalFonts.get('FZShuTi')); fontMapper.put('華文細黑', PhysicalFonts.get('STXihei')); fontMapper.put('宋體擴展', PhysicalFonts.get('simsun-extB')); fontMapper.put('仿宋_GB2312', PhysicalFonts.get('FangSong_GB2312')); fontMapper.put('新細明體', PhysicalFonts.get('SimSun')); pkg.setFontMapper(fontMapper); Docx4J.toPDF(pkg, new FileOutputStream(target));} catch (FileNotFoundException e) { e.printStackTrace();} catch (Docx4JException e) { e.printStackTrace();} catch (Exception e) { e.printStackTrace();}}}三、轉換結果
SLF4J: Failed to load class 'org.slf4j.impl.StaticLoggerBinder'.SLF4J: Defaulting to no-operation (NOP) logger implementationSLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.Using pdbs 420=7mmUsing pdbs 420=7mm
有一點報錯,不過并不影響pdf的生成,打開生成的pdf,內容也是完整的。算是完成了吧,只要再寫一個for循環,去遍歷所有的文檔就可以了。但是后來發現轉換下來的pdf數量少了10個,所有的文檔并沒有全都轉換成功。
四、后續研究排查一番,發現這些文檔中有10個doc文檔,就該就是這10個沒有成功了,單獨拎出來轉換一下,結果就報錯了:
SLF4J: Failed to load class 'org.slf4j.impl.StaticLoggerBinder'.SLF4J: Defaulting to no-operation (NOP) logger implementationSLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.org.docx4j.openpackaging.exceptions.Docx4JException: This file seems to be a binary doc/ppt/xls, not an encrypted OLE2 file containing a doc/pptx/xlsxat org.docx4j.openpackaging.packages.OpcPackage.load(OpcPackage.java:612)at org.docx4j.openpackaging.packages.OpcPackage.load(OpcPackage.java:414)at org.docx4j.openpackaging.packages.OpcPackage.load(OpcPackage.java:287)at org.docx4j.openpackaging.packages.OpcPackage.load(OpcPackage.java:265)at org.docx4j.openpackaging.packages.WordprocessingMLPackage.load(WordprocessingMLPackage.java:168)at org.docx4j.Docx4J.load(Docx4J.java:232)at com.convert.test.ConvertTest.word2pdf(ConvertTest.java:26)at com.convert.test.ConvertTest.main(ConvertTest.java:19)
This file seems to be a binary doc/ppt/xls, not an encrypted OLE2 file containing a doc/pptx/xlsx“此文件似乎是一個二進制文件doc/ppt/xls,而不是包含doc/pptx/xlsx的加密OLE2文件”貌似docx4j并不能完美的支持所有的word文檔,至少doc文檔并不能支持。我想到之前有小伙伴也遇到過這樣問題,后來說是用了永中的office轉換,索性今天自己也來嘗試一下。
三下五除二,一頓操作,永中office官網上的office直接就能把我的doc文檔轉成html展示在瀏覽器上,心細如塵的我,還在其官網上發現有一款“PDF工具集”的產品:
在文章的右側有“開發者”選項,可以直接點擊它進入到轉換的界面。進入之后,發現永中支持的格式還是不少的,在頁面的上半部分就列出了當前支持的所有格式:

繼續向下滾動鼠標滾輪,到達文檔轉換的位置:
可以直接點擊上傳一份doc文檔,等待上傳完畢,就可以直接將doc文檔轉換成PDF文檔了,這樣一來,不管多少個文件,都能一鍵實現word文件轉換成pdf文件,小伙伴們再也不用擔心了。
五、總結其實,目前市面上已有的文檔轉換類的產品非常多,市場競爭十分激烈。但依舊不妨礙有好的產品涌現出來,受到一眾用戶的喜歡和追捧。
一款好的產品一定是契合用戶的本性,能夠對用戶形成一種強大的吸引力,將其牢牢“粘住”。就像永中的這款產品,緊跟市場需求,更看到了用戶的痛點,真正做到用一款簡單、實用、好操作的產品,贏得市場,更贏得了用戶!
到此這篇關于JAVA實現DOC轉PDF的示例代碼的文章就介紹到這了,更多相關JAVA實現DOC轉PDF功能內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:
1. React+umi+typeScript創建項目的過程2. .Net core 的熱插拔機制的深入探索及卸載問題求救指南3. ASP調用WebService轉化成JSON數據,附json.min.asp4. SharePoint Server 2019新特性介紹5. 三個不常見的 HTML5 實用新特性簡介6. 解決ASP中http狀態跳轉返回錯誤頁的問題7. ASP中常用的22個FSO文件操作函數整理8. 無線標記語言(WML)基礎之WMLScript 基礎第1/2頁9. ASP.NET Core 5.0中的Host.CreateDefaultBuilder執行過程解析10. ASP編碼必備的8條原則
 網公網安備
網公網安備