python數據分析之DataFrame內存優化
💃今天看案例的時候看見了一個關于pandas數據的內存壓縮功能,特地來記錄一下。
🎒先說明一下情況,pandas處理幾百兆的dataframe是沒有問題的,但是我們在處理幾個G甚至更大的數據時,就會特別占用內存,對內存小的用戶特別不好,所以對數據進行壓縮是很有必要的。
1. pandas查看數據占用大小給大家看一下這么查看自己的內存大小(user_log是dataframe的名字)
#方法1 就是使用查看dataframe信息的命令user_log.info()#方法2 使用memory_usage()或者getsizeof(user_log)import timeimport sysprint(’all_data占據內存約: {:.2f} GB’.format(user_log.memory_usage().sum()/ (1024**3)))print(’all_data占據內存約: {:.2f} GB’.format(sys.getsizeof(user_log)/(1024**3)))
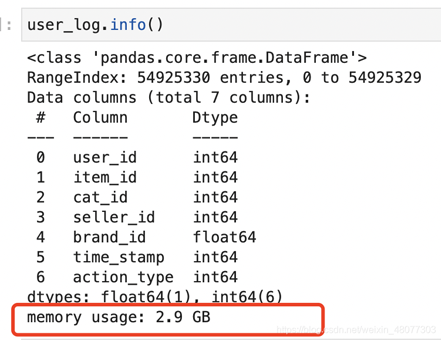
我這里有個dataframe文件叫做user_log,原始大小為1.91G,然后pandas讀取出來,內存使用了2.9G。
看一下原始數據大小:1.91G
pandas讀取后的內存消耗:2.9G
我們這里主要采用對數值型類型的數據進行降級,說一下降級是什么意思意思呢,可以比喻為一個一個抽屜,你有一個大抽屜,但是你只裝了鑰匙,這就會有很多空間浪費掉,如果我們將鑰匙放到一個小抽屜里,就可以節省很多空間,就像字符的類型int32 比int8占用空間大很多,但是我們的數據使用int8類型就夠了,這就導致數據占用了很多空間,我們要做的就是進行數據類型轉換,節省內存空間。
壓縮數值的這段代碼是從天池大賽的某個項目中看見的,查閱資料后發現,大家壓縮內存都是基本固定的函數形式
def reduce_mem_usage(df): starttime = time.time() numerics = [’int16’, ’int32’, ’int64’, ’float16’, ’float32’, ’float64’] start_mem = df.memory_usage().sum() / 1024**2 for col in df.columns:col_type = df[col].dtypesif col_type in numerics: c_min = df[col].min() c_max = df[col].max() if pd.isnull(c_min) or pd.isnull(c_max):continue if str(col_type)[:3] == ’int’:if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max: df[col] = df[col].astype(np.int8)elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max: df[col] = df[col].astype(np.int16)elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max: df[col] = df[col].astype(np.int32)elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max: df[col] = df[col].astype(np.int64) else:if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max: df[col] = df[col].astype(np.float16)elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max: df[col] = df[col].astype(np.float32)else: df[col] = df[col].astype(np.float64) end_mem = df.memory_usage().sum() / 1024**2 print(’-- Mem. usage decreased to {:5.2f} Mb ({:.1f}% reduction),time spend:{:2.2f} min’.format(end_mem, 100*(start_mem-end_mem)/start_mem, (time.time()-starttime)/60)) return df
用壓縮的方式將數據導入user_log2中
#首先讀取到csv中如何傳入函數生稱新的csvuser_log2=reduce_mem_usage(pd.read_csv(r’/Users/liucong/MainFiles/ML/tianchi/tianmiao/user_log_format1.csv’))
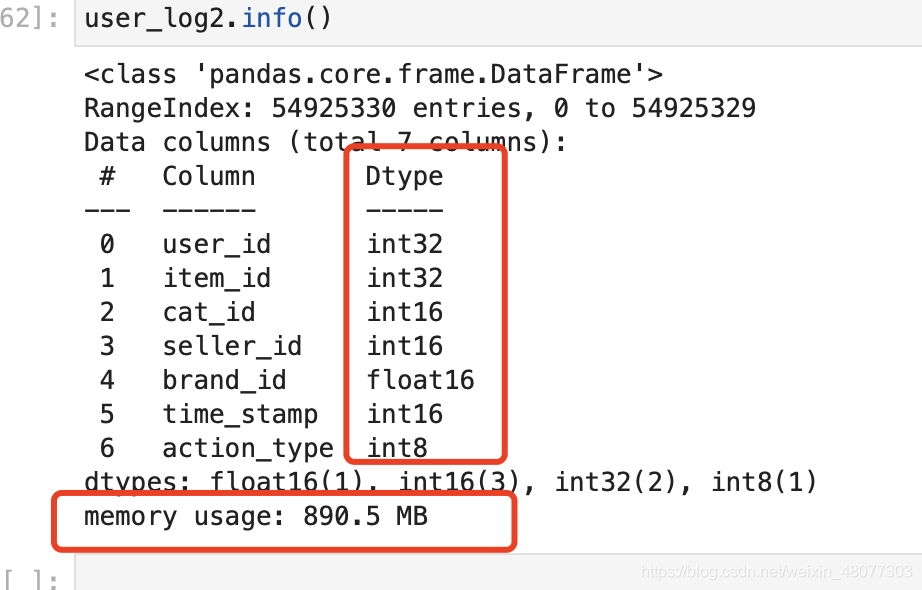
讀取成功:內訓大小為890.48m 減少了69.6%,效果顯著

查看壓縮后的數據集信息:類型發生了變化,數量變小了
《天池大賽》《kaggle大賽》鏈接: pandas處理datafarme節約內存.
到此這篇關于python數據分析之DataFrame內存優化的文章就介紹到這了,更多相關python DataFrame內存優化內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:

 網公網安備
網公網安備