分析如何在Python中解析和修改XML
XML代表可擴(kuò)展標(biāo)記語(yǔ)言。它在外觀上類似于HTML,但XML用于數(shù)據(jù)表示,而HTML用于定義正在使用的數(shù)據(jù)。XML專門設(shè)計(jì)用于在客戶端和服務(wù)器之間來回發(fā)送和接收數(shù)據(jù)。看看下面的例子:
例子:
<? xml version ='1.0' encoding ='UTF-8' ?> <metadata> <food> <item name ='breakfast' > Idly </item> <price> $2.5 </price> <description> 兩個(gè) idly’s with chutney < /description> <calories> 553 </calories> </food> <food> <item name ='breakfast' > Paper Dosa </item> <price> $2.7 </price> <<calories> 700 </calories> </food> <food> <item name ='breakfast' > Upma </item> <price> $3.65 </price> <description> Rava upma with bajji </description> <calories> 600 </calories> </food> <food> <item name ='breakfast' > Bisi Bele Bath </item> <price> $4.50 </price> <description> Bisi Bele Bath with sev </description> <calories> 400 </calories></food> <food> <item name ='breakfast' > Kesari Bath </item> <price> $1.95 </price> <description> 藏紅花甜拉瓦 </description> <calories> 950 </calories> </食物> </元數(shù)據(jù)>
上面的示例顯示了我命名為“Sample.xml”的文件的內(nèi)容,我將在此Python XML解析器教程中為所有即將推出的示例使用相同的內(nèi)容。
二、Python XML解析模塊Python允許使用兩個(gè)模塊解析這些XML文檔,即xml.etree.ElementTree模塊和Minidom(最小DOM實(shí)現(xiàn))。解析意味著從文件中讀取信息并通過識(shí)別該特定XML文件的部分將其拆分為多個(gè)部分。讓我們進(jìn)一步了解如何使用這些模塊來解析XML數(shù)據(jù)。
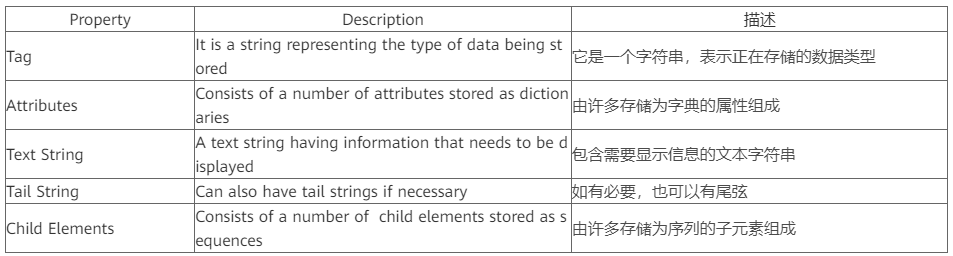
2.1、xml.etree.ElementTree模塊該模塊幫助我們?cè)跇浣Y(jié)構(gòu)中格式化XML數(shù)據(jù),這是分層數(shù)據(jù)的最自然表示。元素類型允許在內(nèi)存中存儲(chǔ)分層數(shù)據(jù)結(jié)構(gòu),并具有以下屬性:
ElementTree是一個(gè)包裝元素結(jié)構(gòu)并允許與XML相互轉(zhuǎn)換的類。現(xiàn)在讓我們嘗試使用python模塊解析上述XML文件。
有兩種使用“ElementTree”模塊解析文件的方法。第一個(gè)是使用parse()函數(shù),第二個(gè)是fromstring()函數(shù)。parse()函數(shù)解析作為文件提供的XML文檔,而fromstring解析作為字符串提供的XML,即在三引號(hào)內(nèi)。
使用parse()函數(shù):
如前所述,該函數(shù)采用文件格式的XML來解析它。看下面的例子:
例子:
import xml.etree.ElementTree as ETmytree = ET.parse(’sample.xml’)myroot = mytree.getroot()
如您所見,您需要做的第一件事是導(dǎo)入xml.etree.ElementTree模塊。然后,parse()方法解析“Sample.xml”文件。getroot()方法返回“Sample.xml”的根元素。
執(zhí)行上述代碼時(shí),您不會(huì)看到返回的輸出,但不會(huì)出現(xiàn)表明代碼已成功執(zhí)行的錯(cuò)誤。要檢查根元素,您可以簡(jiǎn)單地使用print語(yǔ)句,如下所示:
例子:
import xml.etree.ElementTree as ETmytree = ET.parse(’sample.xml’)myroot = mytree.getroot()print(myroot)
輸出:
<元素’元數(shù)據(jù)’在0x033589F0>
上面的輸出表明我們的XML文檔中的根元素是“元數(shù)據(jù)”。
使用fromstring()函數(shù):
您還可以使用fromstring()函數(shù)來解析您的字符串?dāng)?shù)據(jù)。如果要執(zhí)行此操作,請(qǐng)將XML作為字符串傳遞給三引號(hào),如下所示:
import xml.etree.ElementTree as ETdata=’’’<?xml version='1.0' encoding='UTF-8'?><metadata><food> <item name='breakfast'>Idly</item> <price>$2.5</price> <description> Two idly’s with chutney </description> <calories>553</calories></food></metadata>’’’myroot = ET.fromstring(data)#print(myroot)print(myroot.tag)
上面的代碼將返回與前一個(gè)相同的輸出。請(qǐng)注意,用作字符串的XML文檔只是“Sample.xml”的一部分,我使用它來提高可見性。您也可以使用完整的XML文檔。
您還可以使用“標(biāo)簽”對(duì)象檢索根標(biāo)簽,如下所示:
例子:
print(myroot.tag)
輸出:
元數(shù)據(jù)
您還可以通過指定要在輸出中看到的字符串部分來對(duì)標(biāo)簽字符串輸出進(jìn)行切片。
例子:
print(myroot.tag[0:4])
輸出:
元
如前所述,標(biāo)簽也可以具有字典屬性。要檢查根標(biāo)記是否具有任何屬性,您可以使用“attrib”對(duì)象,如下所示:
例子:
print(myroot.attrib)
輸出:
{}
如您所見,輸出是一個(gè)空字典,因?yàn)槲覀兊母鶚?biāo)簽沒有屬性。
尋找感興趣的元素:
根也由子標(biāo)簽組成。要檢索根標(biāo)記的子項(xiàng),您可以使用以下命令:
例子:
print(myroot[0].tag)
輸出:
食物
現(xiàn)在,如果要檢索根的所有第一個(gè)子標(biāo)簽,可以使用for循環(huán)迭代它,如下所示:
例子:
for x in myroot[0]: print(x.tag, x.attrib)
輸出:
item {’name’: ’breakfast’}價(jià)格{}描述{}卡路里{}
返回的所有項(xiàng)目都是食物的子屬性和標(biāo)簽。
要使用ElementTree將文本從XML中分離出來,您可以使用text屬性。例如,如果我想檢索有關(guān)第一個(gè)食品的所有信息,我應(yīng)該使用以下代碼:
例子:
for x in myroot[0]:print(x.text)
輸出:
懶懶地$ 2.5兩悠閑地與酸辣醬的553
可以看到,第一項(xiàng)的文本信息已經(jīng)作為輸出返回了。現(xiàn)在,如果您想顯示具有特定價(jià)格的所有商品,您可以使用get()方法。此方法訪問元素的屬性。
例子:
for x in myroot.findall(’food’): item =x.find(’item’).text price = x.find(’price’).text print(item, price)
輸出:
Idly$2.5Paper Dosa$2.7Upma$3.65Bisi Bele Bath$4.50Kesari Bath$1.95
上面的輸出顯示了所有必需的項(xiàng)目以及每個(gè)項(xiàng)目的價(jià)格。使用ElementTree,您還可以修改XML文件。
修改XML文件:
可以操作XML文件中的元素。為此,您可以使用set()函數(shù)。讓我們首先看看如何向XML添加一些東西。
添加到XML:
以下示例顯示了如何在項(xiàng)目描述中添加內(nèi)容。
例子:
for description in myroot.iter(’description’): new_desc = str(description.text)+’wil be served’ description.text = str(new_desc) description.set(’updated’, ’yes’) mytree.write(’new.xml’)
write()函數(shù)幫助創(chuàng)建一個(gè)新的xml文件并將更新的輸出寫入相同的文件。但是,您也可以使用相同的功能修改原始文件。執(zhí)行完上述代碼后,您將能夠看到已創(chuàng)建具有更新結(jié)果的新文件。

上圖顯示了對(duì)我們食品的修改描述。要添加新的子標(biāo)簽,您可以使用SubElement()方法。例如,如果您想在第一項(xiàng)Idly中添加一個(gè)新的專業(yè)標(biāo)簽,您可以執(zhí)行以下操作:
例子:
ET.SubElement(myroot[0], ’speciality’)for x in myroot.iter(’speciality’): new_desc = ’South Indian Special’ x.text = str(new_desc) mytree.write(’output5.xml’)
輸出:
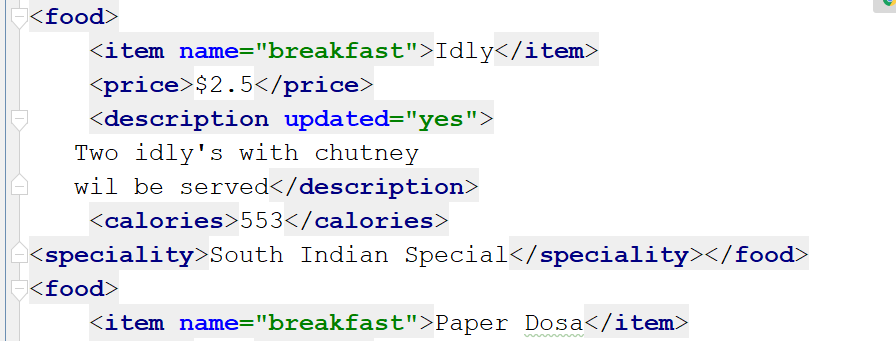
如您所見,在第一個(gè)食品標(biāo)簽下添加了一個(gè)新標(biāo)簽。通過在[]括號(hào)內(nèi)指定下標(biāo),您可以在任何地方添加標(biāo)簽。現(xiàn)在讓我們看一下如何使用此模塊刪除項(xiàng)目。
從XML中刪除:
要使用ElementTree刪除屬性或子元素,您可以使用pop()方法。此方法將刪除用戶不需要的所需屬性或元素。
例子:
myroot[0][0].attrib.pop(’name’, None) # create a new XML file with the resultsmytree.write(’output5.xml’)
輸出:

上圖顯示name屬性已從item標(biāo)記中刪除。要?jiǎng)h除完整的標(biāo)簽,您可以使用相同的pop()方法,如下所示:
例子:
myroot[0].remove(myroot[0][0])mytree.write(’output6.xml’)
輸出:
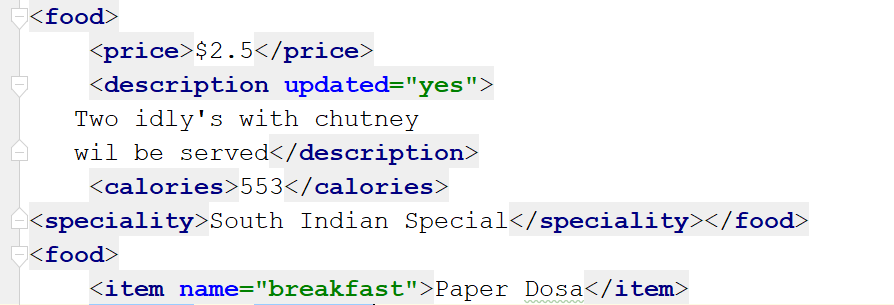
輸出顯示食品標(biāo)簽的第一個(gè)子元素已被刪除。如果要?jiǎng)h除所有標(biāo)簽,可以使用clear()函數(shù),如下所示:
例子:
myroot[0].clear()mytree.write(’output7.xml’)
輸出:
執(zhí)行上述代碼時(shí),food標(biāo)簽的第一個(gè)子標(biāo)簽將被完全刪除,包括所有子標(biāo)簽。到這里為止,我們一直在使用這個(gè)Python XML解析器教程中的xml.etree.ElementTree模塊。現(xiàn)在讓我們看看如何使用Minidom解析XML。
2.2、xml.dom.minidom模塊這個(gè)模塊基本上是由精通DOM(文檔對(duì)象模塊)的人使用的。DOM應(yīng)用程序通常首先將XML解析為DOM。在xml.dom.minidom中,這可以通過以下方式實(shí)現(xiàn):
使用parse()函數(shù):
第一種方法是通過提供要解析的XML文件作為參數(shù)來使用parse()函數(shù)。例如:
例子:
from xml.dom import minidomp1 = minidom.parse('sample.xml');
執(zhí)行此操作后,您將能夠拆分XML文件并獲取所需的數(shù)據(jù)。您還可以使用此函數(shù)解析打開的文件。
例子:
dat=open(’sample.xml’)p2=minidom.parse(dat)
在這種情況下,存儲(chǔ)打開文件的變量作為參數(shù)提供給解析函數(shù)。
使用parseString()方法:
當(dāng)您想要提供要作為字符串解析的XML時(shí),將使用此方法。
例子:
p3 = minidom.parseString(’<myxml>Using<empty/> parseString</myxml>’)
您可以使用上述任何一種方法來解析XML。現(xiàn)在讓我們嘗試使用此模塊獲取數(shù)據(jù)。
尋找感興趣的元素:
在我的文件被解析后,如果我嘗試打印它,返回的輸出會(huì)顯示一條消息,表明存儲(chǔ)解析數(shù)據(jù)的變量是DOM對(duì)象。
例子:
dat=minidom.parse(’sample.xml’)print(dat)
輸出:
<xml.dom.minidom.Document對(duì)象在0x03B5A308>
使用GetElementByTagName訪問元素:
例子:
tagname= dat.getElementsByTagName(’item’)[0]print(tagname)
如果我嘗試使用GetElementByTagName方法獲取第一個(gè)元素,我將看到以下輸出:
輸出:
<DOM元素:0xc6bd00處的項(xiàng)目>
請(qǐng)注意,只返回了一個(gè)輸出,因?yàn)闉榱朔奖阄沂褂昧薣0]下標(biāo),這將在進(jìn)一步的示例中刪除。
要訪問屬性的值,我必須按如下方式使用value屬性:
例子:
dat = minidom.parse(’sample.xml’)tagname= dat.getElementsByTagName(’item’)print(tagname[0].attributes[’name’].value)
輸出:
早餐
要檢索這些標(biāo)簽中存在的數(shù)據(jù),您可以使用data屬性,如下所示:
例子:
print(tagname[1].firstChild.data)
輸出:
紙Dosa
您還可以使用value屬性拆分和檢索屬性的值。
例子:
print(items[1].attributes[’name’].value)
輸出:
早餐
要打印出我們菜單中可用的所有項(xiàng)目,您可以遍歷這些項(xiàng)目并返回所有項(xiàng)目。
例子:
for x in items: print(x.firstChild.data)
輸出:
袖手旁觀紙DOSAUPMA碧斯百麗沐浴Kesari浴
要計(jì)算菜單上的項(xiàng)目數(shù),您可以使用len()函數(shù),如下所示:
例子:
print(len(items))
輸出指定我們的菜單包含5個(gè)項(xiàng)目。
這使我們結(jié)束了本Python XML解析器教程。我希望你已經(jīng)清楚地了解了一切。
以上就是分析如何在Python中解析和修改XML的詳細(xì)內(nèi)容,更多關(guān)于Python解析和修改XML的資料請(qǐng)關(guān)注好吧啦網(wǎng)其它相關(guān)文章!
相關(guān)文章:
1. ASP動(dòng)態(tài)網(wǎng)頁(yè)制作技術(shù)經(jīng)驗(yàn)分享2. 使用Hangfire+.NET 6實(shí)現(xiàn)定時(shí)任務(wù)管理(推薦)3. Xml簡(jiǎn)介_動(dòng)力節(jié)點(diǎn)Java學(xué)院整理4. jsp文件下載功能實(shí)現(xiàn)代碼5. 詳解瀏覽器的緩存機(jī)制6. JSP之表單提交get和post的區(qū)別詳解及實(shí)例7. jsp實(shí)現(xiàn)登錄驗(yàn)證的過濾器8. xml中的空格之完全解說9. 如何在jsp界面中插入圖片10. phpstudy apache開啟ssi使用詳解
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備