我是如何用2個Unix命令給MariaDB SQL提速的
譯者 | 薛命燈
我試圖在 MariaDB(MySQL)上運行一個簡單的連接查詢,但性能簡直糟糕透了。下面將介紹我是如何通過兩個簡單的 Unix 命令,將查詢時間從 380 小時降到 12 小時以下的。
下面就是這個查詢,它是 GHTorrent 分析的一部分,我使用了關(guān)系在線分析處理框架 simple-rolap 來實現(xiàn)這個分析。
select distinctproject_commits.project_id,date_format(created_at, ‘%x%v1") as week_commitfrom project_commitsleft join commitson project_commits.commit_id = commits.id;
兩個連接字段都有索引。不過,MariaDB 是通過對 project_commits 進行全表掃描和對 commits 進行索引查找來實現(xiàn)連接的。這可以從 EXPLAIN 的輸出看出來。
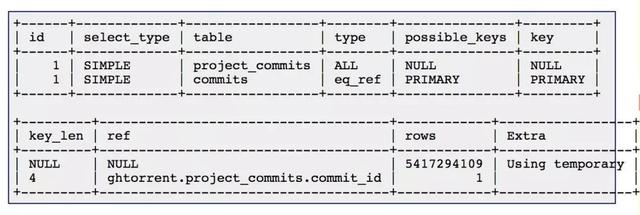
這兩個表中的記錄比較多:project_commits 有 50 億行記錄,commits 有 8.47 億行記錄。服務(wù)器的內(nèi)存比較小,只有 16GB。所以很可能是因為內(nèi)存放不下那么大的索引,需要讀取磁盤,因此嚴(yán)重影響到了性能。從 pmonitor 對臨時表的分析結(jié)果來看,這個查詢已經(jīng)運行半天了,還需要 373 個小時才能運行完。
/home/mysql/ghtorrent/project_commits#P#p0.MYD 6.68% ETA 373:38:11
在我看來,這個太過分了,因為排序合并連接(sort-merge join)所需的 I/O 時間應(yīng)該要比預(yù)計的執(zhí)行時間要低一個數(shù)量級。我在 dba.stackexchange.com 上尋求幫助,有人給出了一些建議讓我嘗試,但我沒有信心它們能夠解決我的問題。我嘗試了第一個建議,結(jié)果并不樂觀。嘗試每個建議都需要至少半天的時間,后來,我決定采用一種我認(rèn)為可以有效解決這個問題的辦法。
我將這兩個表導(dǎo)出到文件中,使用 Unix 的 join 命令將它們連接在一起,將結(jié)果傳給 uniq,把重復(fù)的行移除掉,然后將結(jié)果導(dǎo)回到數(shù)據(jù)庫。導(dǎo)入過程(包括重建索引)從 20:41 開始,到第二天的 9:53 結(jié)束。以下是具體操作步驟。
1. 將數(shù)據(jù)庫表導(dǎo)出為文本文件
我先導(dǎo)出連接兩個表需要用到的字段,并按照連接字段進行排序。為了確保排序順序與 Unix 工具的排序順序兼容,我將字段轉(zhuǎn)換為字符類型。
我將以下 SQL 查詢的輸出保存到文件 commits_week.txt 中。
select cast(id as char) as cid,date_format(created_at, ‘%x%v1") as week_commitfrom commitsorder by cid;
然后將以下 SQL 查詢的輸出保存到 project_commits.txt 文件中:
select cast(commit_id as char) as cid, project_idfrom project_commitsorder by cid;
這樣就生成了以下兩個文件。
-rw-r–r– 1 dds dds 15G Aug 4 21:09 commits_week.txt
-rw-r–r– 1 dds dds 93G Aug 5 00:36 project_commits.txt
為了避免內(nèi)存不足,我使用 –quick 選項來運行 mysql 客戶端,否則客戶端會在輸出結(jié)果之前嘗試收集所有的記錄。
2. 使用 Unix 命令行工具處理文件
接下來,我使用 Unix 的 join 命令來連接這兩個文本文件。這個命令線性掃描兩個文件,并將第一個字段相同的記錄組合在一起。由于文件中的記錄已經(jīng)排好序,因此整個過程完成得很快,幾乎就是 I/O 的速度。我還將連接的結(jié)果傳給 uniq,用以消除重復(fù)記錄,這就解決了原始查詢中的 distinct 問題。同樣,在已經(jīng)排好序的輸出結(jié)果上,可以通過簡單的線性掃描完成去重。
這是我運行的 Unix 命令。
join commits_week.txt project_commits.txt | uniq >joined_commits.txt
經(jīng)過一個小時的處理,我得到了想要的結(jié)果。
-rw-r–r– 1 dds dds 133G Aug 5 01:40 joined_commits.txt
3. 將文本文件導(dǎo)回數(shù)據(jù)庫
最后,我將文本文件導(dǎo)回數(shù)據(jù)庫。
create table half_life.week_commits_all (project_id INT(11) not null,week_commit CHAR(7)) ENGINE=MyISAM;load data local infile ‘joined_commits.txt"into table half_life.week_commits_allfields terminated by ‘ ‘;
結(jié)語
理想情況下,MariaDB 應(yīng)該支持排序合并連接,并且在預(yù)測到備用策略的運行時間過長時,優(yōu)化器應(yīng)該使用排序合并連接。但在此之前,使用 70 年代設(shè)計的 Unix 命令就可以解決這個問題。
相關(guān)文章:
1. MySQL修改字符集的實戰(zhàn)教程2. 關(guān)于Oracle中sqlldr的用法大全3. 探討SQL Server 2005.NET CLR編程4. SQL Server中, DateTime (日期)型操作5. Oracle中的高效SQL編寫PARALLEL解析6. Microsoft SQL Server 查詢處理器的內(nèi)部機制與結(jié)構(gòu)(1)7. 使用SQL語句快速獲取SQL Server數(shù)據(jù)字典8. mysql數(shù)據(jù)庫之count()函數(shù)和sum()函數(shù)用法及區(qū)別說明9. SQL SERVER 2005 EXPRESS不能遠(yuǎn)程連接的問題10. SQL Server 2000之日志傳送功能-設(shè)定
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備