Python爬取網頁requests亂碼
問題描述
**之前有在裁判文書上爬取數據,這段時間重新運行爬蟲后發現無法獲取網頁數據,找了一下發現requests網頁源碼返回的是亂碼**
(如下截取一部分返回的數據:<meta http-equiv='Content-Type' content='text/html; charset=utf-8'><meta ) 不知道是不是網站對網頁內容進行了加密,請問如何解決這個問題?謝謝!
不知道是不是網站對網頁內容進行了加密,請問如何解決這個問題?謝謝!
截取部分程序源碼:
headers = {’User-Agent’: ’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.104 Safari/537.36’,’Accept’: ’text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8’,’Accept-Language’: ’zh-TW,zh;q=0.8,en-US;q=0.6,en;q=0.4’,’Accept-Encoding’: ’gzip, deflate’,’Connection’: ’keep-alive’,’Content-Type’: ’text/html; charset=utf-8’}html = requests.post(’http://wenshu.court.gov.cn/List/ListContent’, data=data, headers=headers)print(html.text)
但是在審查元素里返回應該返回的數據,請問這哪里出現了問題?
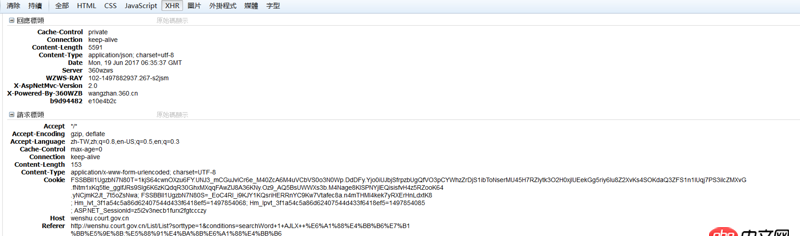
之前程序正常運行時返回的數據是這樣的:
問題解答
回答1:ajax 加載的結果頁面,如果在 network 里獲取不到類似 json 的反饋結果。就使用PHANTOMJS來模擬加載。然后匹配爬取。
回答2:你的 html 對象使用的編碼不對,加入一行 html.encoding = html.apparent_encoding根據實際獲取的 text 推測編碼,重新解碼。
回答3:如果你愿意去鉆,給你個參考地址:http://www.qingpingshan.com/j...
回答4:print html.content
相關文章:
1. javascript - 關于apply()與call()的問題2. java - 在用戶不登錄的情況下,用戶如何添加保存到購物車?3. javascript - nginx反向代理靜態資源403錯誤?4. java - spring boot 如何打包成asp.net core 那種獨立應用?5. docker網絡端口映射,沒有方便點的操作方法么?6. 安全性測試 - nodejs中如何防mySQL注入7. docker - 各位電腦上有多少個容器啊?容器一多,自己都搞混了,咋辦呢?8. 推薦好用mysql管理工具?for mac和pc9. Mysql 組合索引最左原則的疑惑10. javascript - 如何將函數計算出的內容傳遞為變量
 網公網安備
網公網安備