文章詳情頁
python - 使用scrapy框架爬百度圖片被墻
瀏覽:103日期:2022-06-30 14:19:37
問題描述
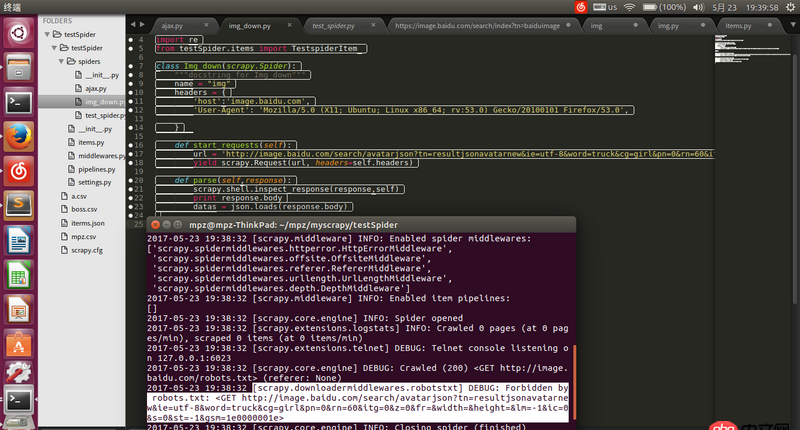
請求地址url是通過firefox查看得到的json的地址,用瀏覽器可以打開,但是用scrapy爬的時候就被ban了求解決辦法。
https://image.baidu.com/searc...
問題解答
回答1:在 settings.py 將 ROBOTSTXT_OBEY = False 試試。
回答2:不要加hearders試試
回答3:贊成樓上,如果還會被墻。可采用scrapy+selenium+phantomjs的方式。
相關(guān)文章:
1. MySQL中無法修改字段名的疑問2. docker images顯示的鏡像過多,狗眼被亮瞎了,怎么辦?3. Matlab和Python編程相似嗎,有兩種都學(xué)過的人可以說說嗎4. 網(wǎng)頁爬蟲 - 用Python3的requests庫模擬登陸B(tài)ilibili總是提示驗證碼錯誤怎么辦?5. javascript - 微信小程序封裝定位問題(封裝異步并可能多次請求)6. android - QQ物聯(lián),視頻通話7. 請教各位大佬,瀏覽器點 提交實例為什么沒有反應(yīng)8. python的前景到底有大?如果不考慮數(shù)據(jù)挖掘,機器學(xué)習(xí)這塊?9. javascript - Web微信聊天輸入框解決方案10. mysql - 怎么讓 SELECT 1+null 等于 1
排行榜

熱門標(biāo)簽
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備