文章詳情頁
網頁爬蟲 - 關于python beautifullsoup解析網頁內容丟失的問題?
瀏覽:130日期:2022-09-23 08:23:07
問題描述

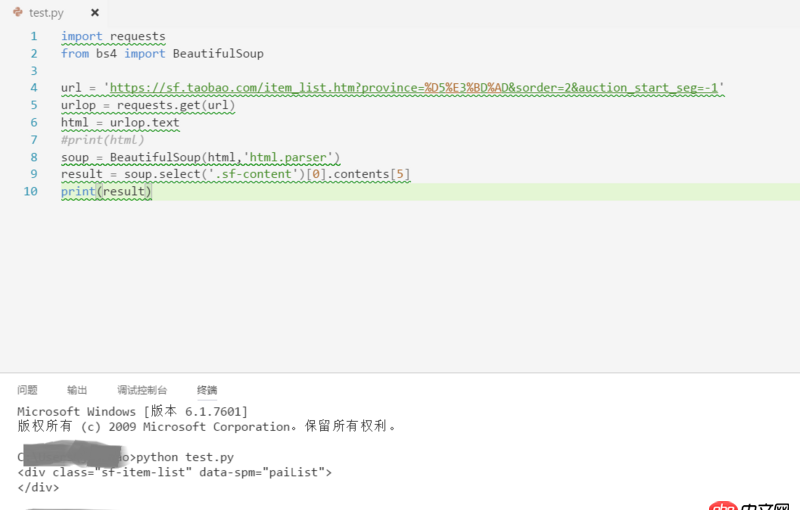
待解析頁面的部分代碼如第一幅圖所示,我自己寫的代碼及運行結果如第二幅圖所示。看到已經有答主提問解析頁面丟失是因為用的是lxml的解析方式,我想說我一直用的是html.parser的方式。希望各位大神不吝賜教~
問題解答
回答1:你們從來都不考慮javascript動態加載的嗎?
回答2:題主,如果你用Chrome F12看的話,里面是會有動態加載的內容的,而這些內容你直接請求頁面的url是拿不到的。建議你點右鍵查看網頁源代碼,對照著F12里面的內容來看,源代碼里沒有的內容,就去查看Network里的其他請求,看有沒有你需要的數據。
相關文章:
排行榜
 網公網安備
網公網安備