Python查找算法之分塊查找算法的實現(xiàn)
分塊查找是二分法查找和順序查找的改進(jìn)方法,分塊查找要求索引表是有序的,對塊內(nèi)結(jié)點(diǎn)沒有排序要求,塊內(nèi)結(jié)點(diǎn)可以是有序的也可以是無序的。
分塊查找就是把一個大的線性表分解成若干塊,每塊中的節(jié)點(diǎn)可以任意存放,但塊與塊之間必須排序。與此同時,還要建立一個索引表,把每塊中的最大值作為索引表的索引值,此索引表需要按塊的順序存放到一個輔助數(shù)組中。查找時,首先在索引表中進(jìn)行查找,確定要找的結(jié)點(diǎn)所在的塊。由于索引表是排序的,因此,對索引表的查找可以采用順序查找或二分查找;然后,在相應(yīng)的塊中采用順序查找,即可找到對應(yīng)的結(jié)點(diǎn)。
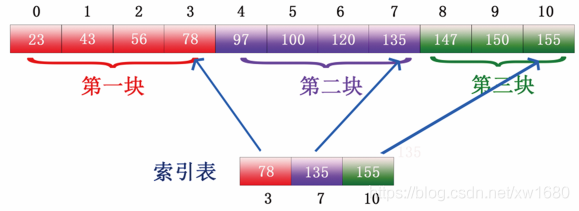
例如,有這樣一列數(shù)據(jù):23、43、56、78、97、100、120、135、147、150。如下圖所示:

想要查找的數(shù)據(jù)是 150,使用分塊查找法步驟如下:
步驟1:將上圖所示的數(shù)據(jù)進(jìn)行分塊,按照每塊長度為 4 進(jìn)行分塊,分塊情況如下圖所示:

說明:每塊的長度是任意指定的,博主在這里用的長度為4,讀者可以根據(jù)自己的需要指定每塊長度。
步驟2:選取各塊中的最大關(guān)鍵字構(gòu)成一個索引表,即選取上圖所示的各塊的最大值,第一塊最大的值是 78,第二塊最大的值是 135,第三塊最大值是 155,形成的索引表如下圖所示:
步驟3:用順序查找或者二分查找判斷想要查找數(shù)據(jù) 150 在上圖所示的索引表中的哪塊內(nèi)容中,這里博主用的是二分查找法,即先取中間值 135 與 150 比較,如下圖所示:
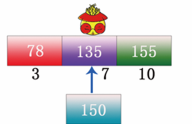
步驟4:結(jié)果是中間位置的數(shù)據(jù) 135 比目標(biāo)數(shù)據(jù) 150 小,因此目標(biāo)數(shù)據(jù)在 135 的下一塊內(nèi)。將數(shù)據(jù)定位在第 3 塊內(nèi),此時將第 3 塊內(nèi)的數(shù)據(jù)取出,進(jìn)行順序比較,如下圖所示:

步驟5:通過順序查找第 3 塊的內(nèi)容,終于在第 9 個位置找到目標(biāo)數(shù),此時分塊查找結(jié)束。
總結(jié):至此,分塊查找算法已經(jīng)講解完畢。通過和二分查找法和順序查找法對比來看,分塊查找的速度雖然不如二分查找算法,但比順序查找算法快得多。當(dāng)數(shù)據(jù)很多且塊數(shù)很大時,對索引表可以采用二分查找,這樣能夠進(jìn)一步提高查找的速度。
二、實例:實現(xiàn)分塊查找算法具體代碼如下:
def search(data, key): # 用二分查找 想要查找的數(shù)據(jù)在哪塊內(nèi) length = len(data) # 數(shù)據(jù)列表長度 first = 0 # 第一位數(shù)位置 last = length - 1 # 最后一個數(shù)據(jù)位置 print(f'長度:{length} 分塊的數(shù)據(jù)是:{data}') # 輸出分塊情況 while first <= last:mid = (last + first) // 2 # 取中間位置if data[mid] > key: # 中間數(shù)據(jù)大于想要查的數(shù)據(jù) last = mid - 1 # 將last的位置移到中間位置的前一位elif data[mid] < key: # 中間數(shù)據(jù)小于想要查的數(shù)據(jù) first = mid + 1 # 將first的位置移到中間位置的后一位else: return mid # 返回中間位置 return False# 分塊查找def block(data, count, key): # 分塊查找數(shù)據(jù),data是列表,count是每塊的長度,key是想要查找的數(shù)據(jù) length = len(data) # 表示數(shù)據(jù)列表的長度 block_length = length // count # 一共分的幾塊 if count * block_length != length: # 每塊長度乘以分塊總數(shù)不等于數(shù)據(jù)總長度block_length += 1 # 塊數(shù)加1 print('一共分', block_length, '塊') # 塊的多少 print('分塊情況如下:') for block_i in range(block_length): # 遍歷每塊數(shù)據(jù)block_data = [] # 每塊數(shù)據(jù)初始化for i in range(count): # 遍歷每塊數(shù)據(jù)的位置 if block_i * count + i >= length: # 每塊長度要與數(shù)據(jù)長度比較,一旦大于數(shù)據(jù)長度break # 就退出循環(huán) block_data.append(data[block_i * count + i]) # 每塊長度要累加上一塊的長度result = search(block_data, key) # 調(diào)用二分查找的值if result != False: # 查找的結(jié)果不為False return block_i * count + result # 就返回塊中的索引位置 return Falsedata = [23, 43, 56, 78, 97, 100, 120, 135, 147, 150, 155] # 數(shù)據(jù)列表result = block(data, 4, 150) # 第二個參數(shù)是塊的長度,最后一個參數(shù)是要查找的元素print('查找的值得索引位置是:', result) # 輸出結(jié)果
運(yùn)行結(jié)果如下圖所示:
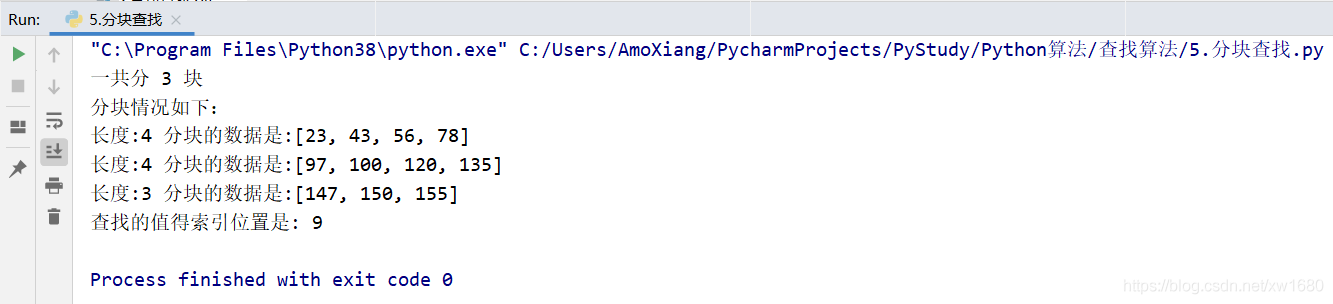
從上面的運(yùn)行結(jié)果看到,當(dāng)查找 150 時,查找結(jié)果完全符合上述描述的步驟。
到此這篇關(guān)于Python查找算法之分塊查找算法的實現(xiàn)的文章就介紹到這了,更多相關(guān)Python 分塊查找算法內(nèi)容請搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. Python 實現(xiàn)勞拉游戲的實例代碼(四連環(huán)、重力四子棋)2. Java GZip 基于內(nèi)存實現(xiàn)壓縮和解壓的方法3. SpringBoot+TestNG單元測試的實現(xiàn)4. jsp+servlet簡單實現(xiàn)上傳文件功能(保存目錄改進(jìn))5. JavaScript數(shù)據(jù)結(jié)構(gòu)之雙向鏈表6. 利用CSS制作3D動畫7. 一款功能強(qiáng)大的markdown編輯器tui.editor使用示例詳解8. 存儲于xml中需要的HTML轉(zhuǎn)義代碼9. SpringBoot整合log4j日志與HashMap的底層原理解析10. .Net加密神器Eazfuscator.NET?2023.2?最新版使用教程
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備