python實(shí)現(xiàn)密度聚類(模板代碼+sklearn代碼)
本人在此就不搬運(yùn)書上關(guān)于密度聚類的理論知識(shí)了,僅僅實(shí)現(xiàn)密度聚類的模板代碼和調(diào)用skelarn的密度聚類算法。有人好奇,為什么有sklearn庫(kù)了還要自己去實(shí)現(xiàn)呢?其實(shí),庫(kù)的代碼是比自己寫的高效且容易,但自己實(shí)現(xiàn)代碼會(huì)對(duì)自己對(duì)算法的理解更上一層樓。
#調(diào)用科學(xué)計(jì)算包與繪圖包import numpy as npimport randomimport matplotlib.pyplot as plt
# 獲取數(shù)據(jù)def loadDataSet(filename): dataSet=np.loadtxt(filename,dtype=np.float32,delimiter=’,’) return dataSet
#計(jì)算兩個(gè)向量之間的歐式距離def calDist(X1 , X2 ): sum = 0 for x1 , x2 in zip(X1 , X2): sum += (x1 - x2) ** 2 return sum ** 0.5
#獲取一個(gè)點(diǎn)的ε-鄰域(記錄的是索引)def getNeibor(data , dataSet , e): res = [] for i in range(dataSet.shape[0]): if calDist(data , dataSet[i])<e: res.append(i) return res
#密度聚類算法def DBSCAN(dataSet , e , minPts): coreObjs = {}#初始化核心對(duì)象集合 C = {} n = dataSet.shape[0] #找出所有核心對(duì)象,key是核心對(duì)象的index,value是ε-鄰域中對(duì)象的index for i in range(n): neibor = getNeibor(dataSet[i] , dataSet , e) if len(neibor)>=minPts: coreObjs[i] = neibor oldCoreObjs = coreObjs.copy() k = 0#初始化聚類簇?cái)?shù) notAccess = list(range(n))#初始化未訪問(wèn)樣本集合(索引) while len(coreObjs)>0: OldNotAccess = [] OldNotAccess.extend(notAccess) cores = coreObjs.keys() #隨機(jī)選取一個(gè)核心對(duì)象 randNum = random.randint(0,len(cores)-1) cores=list(cores) core = cores[randNum] queue = [] queue.append(core) notAccess.remove(core) while len(queue)>0: q = queue[0] del queue[0] if q in oldCoreObjs.keys() :delte = [val for val in oldCoreObjs[q] if val in notAccess]#Δ = N(q)∩Γqueue.extend(delte)#將Δ中的樣本加入隊(duì)列QnotAccess = [val for val in notAccess if val not in delte]#Γ = ΓΔ k += 1 C[k] = [val for val in OldNotAccess if val not in notAccess] for x in C[k]: if x in coreObjs.keys():del coreObjs[x] return C
# 代碼入口dataSet = loadDataSet(r'E:jupytersklearn學(xué)習(xí)sklearn聚類DataSet.txt')print(dataSet)print(dataSet.shape)C = DBSCAN(dataSet, 0.11, 5)draw(C, dataSet)
結(jié)果圖:
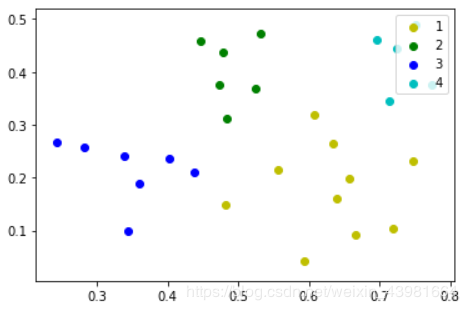
下面是調(diào)用sklearn庫(kù)的實(shí)現(xiàn)
db = skc.DBSCAN(eps=1.5, min_samples=3).fit(dataSet) #DBSCAN聚類方法 還有參數(shù),matric = ''距離計(jì)算方法labels = db.labels_ #和X同一個(gè)維度,labels對(duì)應(yīng)索引序號(hào)的值 為她所在簇的序號(hào)。若簇編號(hào)為-1,表示為噪聲print(’每個(gè)樣本的簇標(biāo)號(hào):’)print(labels)raito = len(labels[labels[:] == -1]) / len(labels) #計(jì)算噪聲點(diǎn)個(gè)數(shù)占總數(shù)的比例print(’噪聲比:’, format(raito, ’.2%’))n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0) # 獲取分簇的數(shù)目print(’分簇的數(shù)目: %d’ % n_clusters_)print('輪廓系數(shù): %0.3f' % metrics.silhouette_score(X, labels)) #輪廓系數(shù)評(píng)價(jià)聚類的好壞for i in range(n_clusters_): print(’簇 ’, i, ’的所有樣本:’) one_cluster = X[labels == i] print(one_cluster) plt.plot(one_cluster[:,0],one_cluster[:,1],’o’)plt.show()
到此這篇關(guān)于python實(shí)現(xiàn)密度聚類(模板代碼+sklearn代碼)的文章就介紹到這了,更多相關(guān)python 密度聚類內(nèi)容請(qǐng)搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. python爬蟲(chóng)實(shí)戰(zhàn)之制作屬于自己的一個(gè)IP代理模塊2. Spring如何使用xml創(chuàng)建bean對(duì)象3. python實(shí)現(xiàn)在內(nèi)存中讀寫str和二進(jìn)制數(shù)據(jù)代碼4. python實(shí)現(xiàn)PolynomialFeatures多項(xiàng)式的方法5. HTML 絕對(duì)路徑與相對(duì)路徑概念詳細(xì)6. python 利用toapi庫(kù)自動(dòng)生成api7. Java程序的編碼規(guī)范(6)8. Android Studio設(shè)置顏色拾色器工具Color Picker教程9. IntelliJ IDEA設(shè)置默認(rèn)瀏覽器的方法10. python實(shí)現(xiàn)讀取類別頻數(shù)數(shù)據(jù)畫水平條形圖案例

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備