使用Python和百度語音識別生成視頻字幕的實現
從視頻中提取音頻
安裝 moviepy
pip install moviepy
相關代碼:
audio_file = work_path + ’out.wav’video = VideoFileClip(video_file)video.audio.write_audiofile(audio_file,ffmpeg_params=[’-ar’,’16000’,’-ac’,’1’])
根據靜音對音頻分段
使用音頻庫 pydub,安裝:
pip install pydub
第一種方法:
# 這里silence_thresh是認定小于-70dBFS以下的為silence,發現小于 sound.dBFS * 1.3 部分超過 700毫秒,就進行拆分。這樣子分割成一段一段的。sounds = split_on_silence(sound, min_silence_len = 500, silence_thresh= sound.dBFS * 1.3)sec = 0for i in range(len(sounds)): s = len(sounds[i]) sec += sprint(’split duration is ’, sec)print(’dBFS: {0}, max_dBFS: {1}, duration: {2}, split: {3}’.format(round(sound.dBFS,2),round(sound.max_dBFS,2),sound.duration_seconds,len(sounds)))

感覺分割的時間不對,不好定位,我們換一種方法:
# 通過搜索靜音的方法將音頻分段# 參考:https://wqian.net/blog/2018/1128-python-pydub-split-mp3-index.htmltimestamp_list = detect_nonsilent(sound,500,sound.dBFS*1.3,1) for i in range(len(timestamp_list)): d = timestamp_list[i][1] - timestamp_list[i][0] print('Section is :', timestamp_list[i], 'duration is:', d)print(’dBFS: {0}, max_dBFS: {1}, duration: {2}, split: {3}’.format(round(sound.dBFS,2),round(sound.max_dBFS,2),sound.duration_seconds,len(timestamp_list)))
輸出結果如下:
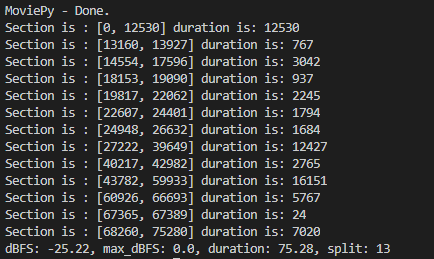
感覺這樣好處理一些
使用百度語音識別
現在百度智能云平臺創建一個應用,獲取 API Key 和 Secret Key:

獲取 Access Token
使用百度 AI 產品需要授權,一定量是免費的,生成字幕夠用了。
’’’百度智能云獲取 Access Token’’’def fetch_token(): params = {’grant_type’: ’client_credentials’, ’client_id’: API_KEY, ’client_secret’: SECRET_KEY} post_data = urlencode(params) if (IS_PY3): post_data = post_data.encode( ’utf-8’) req = Request(TOKEN_URL, post_data) try: f = urlopen(req) result_str = f.read() except URLError as err: print(’token http response http code : ’ + str(err.errno)) result_str = err.reason if (IS_PY3): result_str = result_str.decode() print(result_str) result = json.loads(result_str) print(result) if (’access_token’ in result.keys() and ’scope’ in result.keys()): print(SCOPE) if SCOPE and (not SCOPE in result[’scope’].split(’ ’)): # SCOPE = False 忽略檢查 raise DemoError(’scope is not correct’) print(’SUCCESS WITH TOKEN: %s EXPIRES IN SECONDS: %s’ % (result[’access_token’], result[’expires_in’])) return result[’access_token’] else: raise DemoError(’MAYBE API_KEY or SECRET_KEY not correct: access_token or scope not found in token response’)
使用 Raw 數據進行合成
這里使用百度語音極速版來合成文字,因為官方介紹專有GPU服務集群,識別響應速度較標準版API提升2倍及識別準確率提升15%。適用于近場短語音交互,如手機語音搜索、聊天輸入等場景。 支持上傳完整的錄音文件,錄音文件時長不超過60秒。實時返回識別結果
def asr_raw(speech_data, token): length = len(speech_data) if length == 0: # raise DemoError(’file %s length read 0 bytes’ % AUDIO_FILE) raise DemoError(’file length read 0 bytes’) params = {’cuid’: CUID, ’token’: token, ’dev_pid’: DEV_PID} #測試自訓練平臺需要打開以下信息 #params = {’cuid’: CUID, ’token’: token, ’dev_pid’: DEV_PID, ’lm_id’ : LM_ID} params_query = urlencode(params) headers = { ’Content-Type’: ’audio/’ + FORMAT + ’; rate=’ + str(RATE), ’Content-Length’: length } url = ASR_URL + '?' + params_query # print post_data req = Request(ASR_URL + '?' + params_query, speech_data, headers) try: begin = timer() f = urlopen(req) result_str = f.read() # print('Request time cost %f' % (timer() - begin)) except URLError as err: # print(’asr http response http code : ’ + str(err.errno)) result_str = err.reason if (IS_PY3): result_str = str(result_str, ’utf-8’) return result_str
生成字幕
字幕格式: https://www.cnblogs.com/tocy/p/subtitle-format-srt.html
生成字幕其實就是語音識別的應用,將識別后的內容按照 srt 字幕格式組裝起來就 OK 了。具體字幕格式的內容可以參考上面的文章,代碼如下:
idx = 0for i in range(len(timestamp_list)): d = timestamp_list[i][1] - timestamp_list[i][0] data = sound[timestamp_list[i][0]:timestamp_list[i][1]].raw_data str_rst = asr_raw(data, token) result = json.loads(str_rst) # print('rst is ', result) # print('rst is ', rst[’err_no’][0]) if result[’err_no’] == 0: text.append(’{0}n{1} --> {2}n’.format(idx, format_time(timestamp_list[i][0]/ 1000), format_time(timestamp_list[i][1]/ 1000))) text.append( result[’result’][0]) text.append(’n’) idx = idx + 1 print(format_time(timestamp_list[i][0]/ 1000), 'txt is ', result[’result’][0])with open(srt_file,'r+') as f: f.writelines(text)
總結
我在視頻網站下載了一個視頻來作測試,極速模式從速度和識別率來說都是最好的,感覺比網易見外平臺還好用。
到此這篇關于使用Python和百度語音識別生成視頻字幕的文章就介紹到這了,更多相關Python 百度語音識別生成視頻字幕內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:
 網公網安備
網公網安備