Java爬蟲(Jsoup與WebDriver)的使用
一、Jsoup爬蟲
jsoup 是一款Java 的HTML解析器,可直接解析某個URL地址、HTML文本內容。它提供了一套非常省力的API,可通過DOM,CSS以及類似于jQuery的操作方法來取出和操作數據。
以博客園首頁為例
1、idea新建maven工程
pom.xml導入jsoup依賴
<dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.12.1</version></dependency>
jsoup代碼
package com.blb;import org.jsoup.Jsoup;import org.jsoup.nodes.Document;import org.jsoup.nodes.Element;import org.jsoup.select.Elements;import java.io.IOException;public class jsoup { public static void main(String[] args) { //博客園首頁url final String url= 'https://www.cnblogs.com'; try { //先獲得的是整個頁面的html標簽頁面 Document doc= Jsoup.connect(url).get(); System.out.println(doc); //可以通過元素的標簽獲取html中的特定元素 Elements title = doc.select('title'); String t = title.text(); System.out.println(t); //可以通過元素的id獲取html中的特定元素 Element site_nav_top = doc.getElementById('site_nav_top'); String s = site_nav_top.text(); System.out.println(s); } catch (IOException e) { e.printStackTrace(); } }}
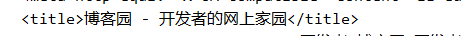

該方式有個很大的局限性,就是通過jsoup爬蟲只適合爬靜態網頁,所以只能爬當前頁面的信息。
二、Webdriver技術
Selenium是一個瀏覽器自動化操作框架。selenium主要由三種工具組成。1.第一個工具——SeleniumIDE,是Firefox的擴展插件,支持用戶錄制和回訪測試。錄制/回訪模式存在局限性,對許多用戶來說并不適合。
2.因此第二個工具——Selenium WebDriver提供了各種語言環境的API來支持更多控制權和編寫符合標準軟件開發實踐的應用程序。
3.最后一個工具——SeleniumGrid幫助工程師使用Selenium API控制分布在一系列機器上的瀏覽器實例,支持并發運行更多測試。
在項目內部,它們分別被稱為“IDE”、“WebDriver”和“Grid”。
什么是 Webdriver ?
官網介紹:
WebDriver is a clean, fast framework for automated testing of webapps.(WebDriver是一個干凈、快速的web應用自動測試框架。)
WebDriver針對各個瀏覽器而開發,取代了嵌入到被測Web應用中的JavaScript。與瀏覽器的緊密集成支持創建更高級的測試,避免了JavaScript安全模型導致的限制。除了來自瀏覽器廠商的支持,WebDriver還利用操作系統級的調用模擬用戶輸入。WebDriver支持Firefox(FirefoxDriver)、IE (InternetExplorerDriver)、Opera (OperaDriver)和Chrome (ChromeDriver)。 它還支持Android (AndroidDriver)和iPhone (IPhoneDriver)的移動應用測試。它還包括一個基于HtmlUnit的無界面實現,稱為HtmlUnitDriver。WebDriver API可以通過Python、Ruby、Java和C#訪問,支持開發人員使用他們偏愛的編程語言來創建測試。
WebDriver如何工作
WebDriver是W3C的一個標準,由Selenium主持。
具體的協議標準可以從http://code.google.com/p/selenium/wiki/JsonWireProtocol#Command_Reference 查看。
從這個協議中我們可以看到,WebDriver之所以能夠實現與瀏覽器進行交互,是因為瀏覽器實現了這些協議。這個協議是使用JOSN通過HTTP進行傳輸。
它的實現使用了經典的Client-Server模式。客戶端發送一個requset,服務器端返回一個response。
我們明確幾個概念。
Client
調用 WebDriverAPI的機器。
Server
運行瀏覽器的機器。Firefox瀏覽器直接實現了WebDriver的通訊協議,而Chrome和IE則是通過ChromeDriver和InternetExplorerDriver實現的。
Session
服務器端需要維護瀏覽器的Session,從客戶端發過來的請求頭中包含了Session信息,服務器端將會執行對應的瀏覽器頁面。
WebElement
這是WebDriverAPI中的對象,代表頁面上的一個DOM元素。
實現:
1.下載瀏覽器驅動,用的是Chrome瀏覽器,下載地址http://chromedriver.storage.googleapis.com/index.html,按對應瀏覽器版本號下載

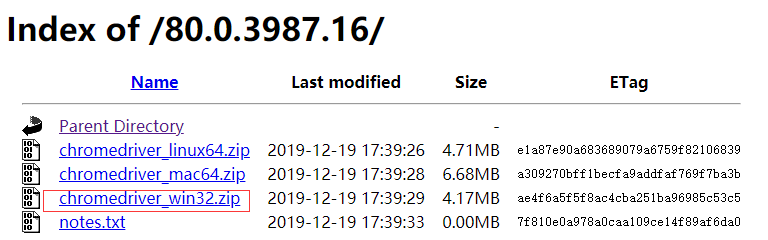
2、idea新建maven工程
pom.xml導入入selinium依賴
<dependency> <groupId>org.seleniumhq.selenium</groupId> <artifactId>selenium-java</artifactId> <version>3.141.59</version> </dependency>
代碼實現:
package com.blb;import org.jsoup.Jsoup;import org.jsoup.nodes.Document;import org.jsoup.select.Elements;import org.openqa.selenium.By;import org.openqa.selenium.WebDriver;import org.openqa.selenium.chrome.ChromeDriver;public class chrome { public static void main(String[] args) { //下載的chromedriver位置 System.setProperty('webdriver.chrome.driver','D:idea_workspaceJsoupsrcmainchromedriver.exe'); //實例化ChromeDriver對象 WebDriver driver = new ChromeDriver(); String url='https://search.51job.com/list/000000,000000,0000,00,9,99,%25E5%25A4%25A7%25E6%2595%25B0%25E6%258D%25AE%25E5%25B7%25A5%25E7%25A8%258B%25E5%25B8%2588,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare='; //打開指定網站 driver.get(url); //解析頁面 String pageSource =driver.getPageSource(); Document jsoup = Jsoup.parse(pageSource); //定義選擇器規則 String rule='#resultList > div:nth-child(4) > p > span > a'; //通過選擇器拿到元素 Elements select = jsoup.select(rule); String s=select.text(); System.out.println(s); //模擬瀏覽器點擊 driver.findElement(By.cssSelector(rule)).click(); }}
爬取電影資源:
package com.blb;import org.jsoup.Jsoup;import org.jsoup.nodes.Document;import org.jsoup.nodes.Element;import org.jsoup.select.Elements;import org.openqa.selenium.WebDriver;import org.openqa.selenium.chrome.ChromeDriver;public class getMovie {private static final String url='http://www.zuidazy5.com';public static void main(String[] args) {System.setProperty('webdriver.chrome.driver','D:idea_workspaceJsoupsrcmainchromedriver.exe');WebDriver driver = new ChromeDriver();driver.get(url);String pageSource = driver.getPageSource();Document jsoup = Jsoup.parse(pageSource);String rule1='body > div.xing_vb > ul> li > span.xing_vb4 > a';Elements select = jsoup.select(rule1);//遍歷當前頁的所有電影詳情入口for (Element e:select){//獲取電影詳情頁鏈接String href = e.attr('href');//進入每個電影詳情頁面driver.get(url+href);String pageSource2= driver.getPageSource();Document jsoup2 = Jsoup.parse(pageSource2);//定義獲取電影信息元素的規則String mname='body > div.warp > div:nth-child(1) > div > div > div.vodInfo > div.vodh > h2';String mpic='body > div.warp > div:nth-child(1) > div > div > div.vodImg > img';String mdirector='body > div.warp > div:nth-child(1) > div > div > div.vodInfo > div.vodinfobox > ul > li:nth-child(2) > span';String mactor='body > div.warp > div:nth-child(1) > div > div > div.vodInfo > div.vodinfobox > ul > li:nth-child(3) > span';String marea='body > div.warp > div:nth-child(1) > div > div > div.vodInfo > div.vodinfobox > ul > li:nth-child(5) > span';String mlanguage='body > div.warp > div:nth-child(1) > div > div > div.vodInfo > div.vodinfobox > ul > li:nth-child(6) > span';String mshowtime='body > div.warp > div:nth-child(1) > div > div > div.vodInfo > div.vodinfobox > ul > li:nth-child(7) > span';String mscore='body > div.warp > div:nth-child(1) > div > div > div.vodInfo > div.vodh > label';String mtimelength='body > div.warp > div:nth-child(1) > div > div > div.vodInfo > div.vodinfobox > ul > li:nth-child(8) > span';String mlastmodifytime='body > div.warp > div:nth-child(1) > div > div > div.vodInfo > div.vodinfobox > ul > li:nth-child(9) > span';String minfo='body > div.warp > div:nth-child(1) > div > div > div.vodInfo > div.vodinfobox > ul > li.cont > div > span.more';String mplayaddress1='#play_1 > ul > li';String mplayaddress2='#play_2 > ul > li';String msv='body > div.warp > div:nth-child(1) > div > div > div.vodInfo > div.vodh > span';//獲取元素信息String sv=jsoup2.select(msv).text();String name = jsoup2.select(mname).text();String pic = jsoup2.select(mpic).attr('src');String director=jsoup2.select(mdirector).text();String actor=jsoup2.select(mactor).text();String area=jsoup2.select(marea).text();String language=jsoup2.select(mlanguage).text();String showtime=jsoup2.select(mshowtime).text();String score=jsoup2.select(mscore).text();String timelength=jsoup2.select(mtimelength).text();String lastmodifytime=jsoup2.select(mlastmodifytime).text();String info=jsoup2.select(minfo).text();String playaddress1 = jsoup2.select(mplayaddress1).text();String playaddress2=jsoup2.select(mplayaddress2).text();//打印電影名System.out.println(name);}}}
為了不顯示瀏覽器爬取過程,可以將chromedriver.exe 換成無頭瀏覽器 phantomjs.exe
下載地址:https://phantomjs.org/download.html
到此這篇關于Java爬蟲(Jsoup與WebDriver)的使用的文章就介紹到這了,更多相關Java Jsoup與WebDriver爬蟲內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:
 網公網安備
網公網安備