java中文亂碼解決之道
隨著計(jì)算機(jī)的發(fā)展、普及,世界各國(guó)為了適應(yīng)本國(guó)的語(yǔ)言和字符都會(huì)自己設(shè)計(jì)一套自己的編碼風(fēng)格,正是由于這種亂,導(dǎo)致存在很多種編碼方式,以至于同一個(gè)二進(jìn)制數(shù)字可能會(huì)被解釋成不同的符號(hào)。為了解決這種不兼容的問(wèn)題,偉大的創(chuàng)想Unicode編碼應(yīng)時(shí)而生!!
UnicodeUnicode又稱為統(tǒng)一碼、萬(wàn)國(guó)碼、單一碼,它是為了解決傳統(tǒng)的字符編碼方案的局限而產(chǎn)生的,它為每種語(yǔ)言中的每個(gè)字符設(shè)定了統(tǒng)一并且唯一的二進(jìn)制編碼,以滿足跨語(yǔ)言、跨平臺(tái)進(jìn)行文本轉(zhuǎn)換、處理的要求。可以想象Unicode作為一個(gè)“字符大容器”,它將世界上所有的符號(hào)都包含其中,并且每一個(gè)符號(hào)都有自己獨(dú)一無(wú)二的編碼,這樣就從根本上解決了亂碼的問(wèn)題。所以Unicode是一種所有符號(hào)的編碼[2]。
Unicode伴隨著通用字符集的標(biāo)準(zhǔn)而發(fā)展,同時(shí)也以書(shū)本的形式對(duì)外發(fā)表,它是業(yè)界的標(biāo)準(zhǔn),對(duì)世界上大部分的文字系統(tǒng)進(jìn)行了整理、編碼,使得電腦可以用更為簡(jiǎn)單的方式來(lái)呈現(xiàn)和處理文字。Unicode至今仍在不斷增修,迄今而至已收入超過(guò)十萬(wàn)個(gè)字符,它備受業(yè)界認(rèn)可,并廣泛地應(yīng)用于電腦軟件的國(guó)際化與本地化過(guò)程。
我們知道Unicode是為了解決傳統(tǒng)的字符編碼方案的局限而產(chǎn)生的,對(duì)于傳統(tǒng)的編碼方式而言,他們都存在一個(gè)共同的問(wèn)題:無(wú)法支持多語(yǔ)言環(huán)境,這對(duì)于互聯(lián)網(wǎng)這個(gè)開(kāi)放的環(huán)境是不允許的。而目前幾乎所有的電腦系統(tǒng)都支持基本拉丁字母,并各自支持不同的其他編碼方式。Unicode為了和它們相互兼容,其首256字符保留給ISO 8859-1所定義的字符,使既有的西歐語(yǔ)系文字的轉(zhuǎn)換不需特別考量;并且把大量相同的字符重復(fù)編到不同的字符碼中去,使得舊有紛雜的編碼方式得以和Unicode編碼間互相直接轉(zhuǎn)換,而不會(huì)丟失任何信息[1]。
實(shí)現(xiàn)方式一個(gè)字符的Unicode編碼是確定的,但是在實(shí)際傳輸過(guò)程中,由于不同系統(tǒng)平臺(tái)的設(shè)計(jì)不一定一致,以及出于節(jié)省空間的目的,對(duì)Unicode編碼的實(shí)現(xiàn)方式有所不同。Unicode的實(shí)現(xiàn)方式稱為Unicode轉(zhuǎn)換格式(Unicode Transformation Format,簡(jiǎn)稱為UTF)[1]。
Unicode是字符集,它主要有UTF-8、UTF-16、UTF-32三種實(shí)現(xiàn)方式。由于UTF-8是目前主流的實(shí)現(xiàn)方式,UTF-16、UTF-32相對(duì)而言使用較少,所以下面就主要介紹UTF-8。
UCS提到Unicode可能有必要了解下,UCS。UCS(Universal Character Set,通用字符集),是由ISO制定的ISO 10646(或稱ISO/IEC 10646)標(biāo)準(zhǔn)所定義的標(biāo)準(zhǔn)字符集。它包括了其他所有字符集,保證了與其他字符集的雙向兼容,即,如果你將任何文本字符串翻譯到UCS格式,然后再翻譯回原編碼,你不會(huì)丟失任何信息。
UCS不僅給每個(gè)字符分配一個(gè)代碼,而且賦予了一個(gè)正式的名字。表示一個(gè)UCS或Unicode值的十六進(jìn)制數(shù)通常在前面加上“U+”,例如“U+0041”代表字符“A”。
Little endian & Big endian由于各個(gè)系統(tǒng)平臺(tái)的設(shè)計(jì)不同,可能會(huì)導(dǎo)致某些平臺(tái)對(duì)字符的理解不同(比如字節(jié)順序的理解)。這時(shí)將會(huì)導(dǎo)致同意字節(jié)流可能會(huì)被解釋為不同的內(nèi)容。如某個(gè)字符的十六進(jìn)制為4E59,拆分為4E、59,在MAC上讀取時(shí)是歐諾個(gè)低位開(kāi)始的,那么MAC在遇到該字節(jié)流時(shí)會(huì)被解析為594E,找到的字符為“奎”,但是在Windows平臺(tái)是從高字節(jié)開(kāi)始讀取,為4E59,找到的字符為“乙”。也就是說(shuō)在Windows平臺(tái)保存的“乙”跑到MAC平臺(tái)上就變成了“奎”。這樣勢(shì)必會(huì)引起混亂,于是在Unicode編碼中采用了大頭(Big endian)、小頭(Little endian)兩種方式來(lái)進(jìn)行區(qū)分。即第一個(gè)字節(jié)在前,就是大頭方式,第二個(gè)字節(jié)在前就是小頭方式。那么這個(gè)時(shí)候就出現(xiàn)了一個(gè)問(wèn)題:計(jì)算機(jī)怎么知道某個(gè)文件到底是采用哪種編碼方式的呢?
Unicode規(guī)范中定義,每一個(gè)文件的最前面分別加入一個(gè)表示編碼順序的字符,這個(gè)字符的名字叫做'零寬度非換行空格'(ZERO WIDTH NO-BREAK SPACE),用FEFF表示。這正好是兩個(gè)字節(jié),而且FF比FE大1。
如果一個(gè)文本文件的頭兩個(gè)字節(jié)是FE FF,就表示該文件采用大頭方式;如果頭兩個(gè)字節(jié)是FF FE,就表示該文件采用小頭方式。
UTF-8UTF-8是一種針對(duì)Unicode的可變長(zhǎng)度字符編碼,可以使用1~4個(gè)字節(jié)表示一個(gè)符號(hào),根據(jù)不同的符號(hào)而變化字節(jié)長(zhǎng)度。它可以用來(lái)表示Unicode標(biāo)準(zhǔn)中的任何字符,且其編碼中的第一個(gè)字節(jié)仍與ASCII兼容,這使得原來(lái)處理ASCII字符的系統(tǒng)無(wú)須或只須做少部份修改,即可繼續(xù)使用。因此,它逐漸成為電子郵件、網(wǎng)頁(yè)及其他存儲(chǔ)或傳送文字的應(yīng)用中,優(yōu)先采用的編碼。
UTF-8使用一到四個(gè)字節(jié)為每個(gè)字符編碼,編碼規(guī)則如下:
1)對(duì)于單字節(jié)的符號(hào),字節(jié)的第一位設(shè)為0,后面7位為這個(gè)符號(hào)的unicode碼。因此對(duì)于英語(yǔ)字母,UTF-8編碼和ASCII碼是相同的。
2)對(duì)于n字節(jié)的符號(hào)(n>1),第一個(gè)字節(jié)的前n位都設(shè)為1,第n+1位設(shè)為0,后面字節(jié)的前兩位一律設(shè)為10。剩下的沒(méi)有提及的二進(jìn)制位,全部為這個(gè)符號(hào)的unicode碼。
轉(zhuǎn)換表如下:
Unicode
UTF-8
0000 ~007F
0XXX XXXX
0080 ~07FF
110X XXXX 10XX XXXX
0800 ~FFFF
1110XXXX 10XX XXXX 10XX XXXX
1 0000 ~1F FFFF
1111 0XXX 10XX XXXX 10XX XXXX 10XX XXXX
20 0000 ~3FF FFFF
1111 10XX 10XX XXXX 10XX XXXX 10XX XXXX 10XX XXXX
400 0000 ~7FFF FFFF
1111 110X 10XX XXXX 10XX XXXX 10XX XXXX 10XX XXXX 10XX XXXX
根據(jù)上面的轉(zhuǎn)換表,理解UTF-8的轉(zhuǎn)換編碼規(guī)則就變得非常簡(jiǎn)單了:第一個(gè)字節(jié)的第一位如果為0,則表示這個(gè)字節(jié)單獨(dú)就是一個(gè)字符;如果為1,連續(xù)多少個(gè)1就表示該字符占有多少個(gè)字節(jié)。
以漢字'嚴(yán)'為例,演示如何實(shí)現(xiàn)UTF-8編碼[3]。
已知'嚴(yán)'的unicode是4E25(100111000100101),根據(jù)上表,可以發(fā)現(xiàn)4E25處在第三行的范圍內(nèi)(0000 0800-0000 FFFF),因此'嚴(yán)'的UTF-8編碼需要三個(gè)字節(jié),即格式是'1110xxxx 10xxxxxx 10xxxxxx'。然后,從'嚴(yán)'的最后一個(gè)二進(jìn)制位開(kāi)始,依次從后向前填入格式中的x,多出的位補(bǔ)0。這樣就得到了,'嚴(yán)'的UTF-8編碼是'11100100 10111000 10100101',轉(zhuǎn)換成十六進(jìn)制就是E4B8A5。
Unicode與UTF-8之間的轉(zhuǎn)換通過(guò)上面的例子我們可以看到'嚴(yán)'的Unicode碼為4E25,UTF-8編碼為E4B8A5,他們兩者是不一樣的,需要通過(guò)程序的轉(zhuǎn)換來(lái)實(shí)現(xiàn),在Window平臺(tái)最簡(jiǎn)單的直觀的方法就是記事本。
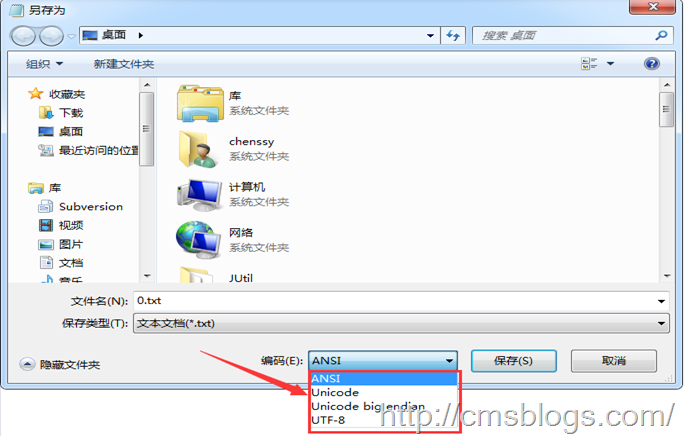
在最下面的'編碼(E)'處有四個(gè)選項(xiàng):ANSI、Unicode、Unicode big endian、UTF-8。
ANSI:記事本的默認(rèn)的編碼方式,對(duì)于英文文件是ASCII編碼,對(duì)于簡(jiǎn)體中文文件是GB2312編碼。注意:不同 ANSI 編碼之間互不兼容,當(dāng)信息在國(guó)際間交流時(shí),無(wú)法將屬于兩種語(yǔ)言的文字,存儲(chǔ)在同一段 ANSI 編碼的文本中
Unicode:UCS-2編碼方式,即直接用兩個(gè)字節(jié)存入字符的Unicode碼。該方式是'小頭'little endian方式。
Unicode big endian:UCS-2編碼方式,'大頭'方式。
UTF-8:閱讀上面(UTF-8)。
>>>實(shí)例:在記事本中輸入'嚴(yán)'字,依次選擇ANSI、Unicode、Unicode big endian、UTF-8四種編碼風(fēng)格,然后另存為,使用EditPlus文本工具使用'16進(jìn)制查看器'進(jìn)行查看,得到如下結(jié)果:

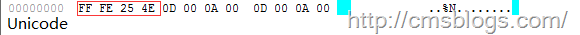


ANSI:兩個(gè)字節(jié)'D1 CF'正是'嚴(yán)'的GB2312編碼。
Unicode:四個(gè)字節(jié)'FF FE 25 4E',其中'FF FE'表示小頭存儲(chǔ)方式,真正的編碼為'25 4E'。
Unicode big endian:四個(gè)字節(jié)'FE FF 4E 25','FE FF'表示大頭存儲(chǔ)方式,真正編碼為'4E 25'。
UTF-8:編碼是六個(gè)字節(jié)'EF BB BF E4 B8 A5',前三個(gè)字節(jié)'EF BB BF'表示這是UTF-8編碼,后三個(gè)'E4B8A5'就是'嚴(yán)'的具體編碼,它的存儲(chǔ)順序與編碼順序是一致的。
相關(guān)文章:
1. android studio實(shí)現(xiàn)簡(jiǎn)單的計(jì)算器(無(wú)bug)2. android 控件同時(shí)監(jiān)聽(tīng)單擊和雙擊實(shí)例3. Python 忽略文件名編碼的方法4. vue使用exif獲取圖片經(jīng)緯度的示例代碼5. 詳解android adb常見(jiàn)用法6. 解決vue頁(yè)面刷新,數(shù)據(jù)丟失的問(wèn)題7. python logging.info在終端沒(méi)輸出的解決8. java——Byte類/包裝類的使用說(shuō)明9. python Selenium 庫(kù)的使用技巧10. python 讀txt文件,按‘,’分割每行數(shù)據(jù)操作
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備