Django-Scrapy生成后端json接口的方法示例
網(wǎng)上的關(guān)于django-scrapy的介紹比較少,該博客只在本人查資料的過(guò)程中學(xué)習(xí)的,如果不對(duì)之處,希望指出改正;
以后的博客可能不會(huì)再出關(guān)于django相關(guān)的點(diǎn);
人心太浮躁,個(gè)人深度不夠,只學(xué)習(xí)了一些皮毛,后面博客只求精,不求多;
希望能堅(jiān)持下來(lái)。加油!
學(xué)習(xí)點(diǎn):
實(shí)現(xiàn)效果 django與scrapy的創(chuàng)建 setting中對(duì)接的位置和代碼段 scrapy_djangoitem使用 scrapy數(shù)據(jù)爬取保存部分 數(shù)據(jù)庫(kù)設(shè)計(jì)以及問(wèn)題部分 django配置實(shí)現(xiàn)效果:

django與scrapy的創(chuàng)建:
django的創(chuàng)建:
django startproject 項(xiàng)目名稱(chēng)
cd 項(xiàng)目名稱(chēng)python manage.py startapp appname
例如:
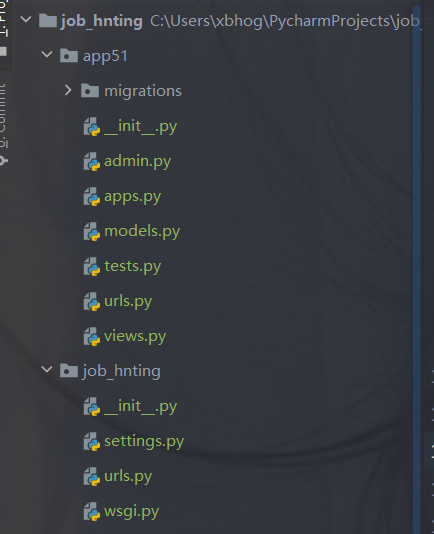
scrapy的創(chuàng)建:
# cd django的根目錄下cd job_hntingscrapy startproject 項(xiàng)目名稱(chēng)#創(chuàng)建爬蟲(chóng)scrapy genspider spidername ’www.xxx.com’
例如:

setting的設(shè)置:
在scrapy框架中的setting指向django,讓django知道有scrapy;
在scrapy中的setting設(shè)置;
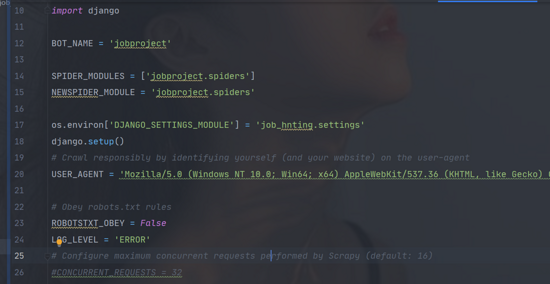
import osimport django#導(dǎo)入os.environ[’DJANGO_SETTINGS_MODULE’] = ’job_hnting.settings’#手動(dòng)初始化django.setup()
如:
scrapy_djangoitem使用:
pip install scrapy_djangoitem
該庫(kù)在scrapy項(xiàng)目下的item中編寫(xiě)引入:
import scrapy# 引入django中app中models文件中的類(lèi)from app51.models import app51data# scrapy與django對(duì)接的庫(kù)from scrapy_djangoitem import DjangoItemclass JobprojectItem(DjangoItem): #引用django下的model中的類(lèi)名 django_model = app51data
數(shù)據(jù)存儲(chǔ)部分對(duì)接在后面解釋?zhuān)F(xiàn)在大體框架完整;
scrapy爬取保存部分:
首先編寫(xiě)scrapy爬蟲(chóng)部分:
我們選取的是51招聘網(wǎng)站的數(shù)據(jù):
爬取分為三個(gè)函數(shù):
主函數(shù) 解析函數(shù) 總頁(yè)數(shù)函數(shù)51job的反爬手段:
將json的數(shù)據(jù)格式隱藏在網(wǎng)頁(yè)結(jié)構(gòu)中,網(wǎng)上教程需要?jiǎng)e的庫(kù)解析(自行了解),
我們的方法是使用正則匹配提取定位到數(shù)據(jù)部分,使用json庫(kù)解析:
# 定位數(shù)據(jù)位置,提取json數(shù)據(jù) search_pattern = 'window.__SEARCH_RESULT__ = (.*?)</script>' jsonText = re.search(search_pattern, response.text, re.M | re.S).group(1)
獲得關(guān)鍵字總頁(yè)數(shù):
# 解析json數(shù)據(jù) jsonObject = json.loads(jsonText) number = jsonObject[’total_page’]
在主函數(shù)中構(gòu)造頁(yè)面url并給到解析函數(shù):
for number in range(1,int(numbers)+1): next_page_url = self.url.format(self.name,number) # print(next_page_url) #構(gòu)造的Urlcallback到data_parse函數(shù)中 yield scrapy.Request(url=next_page_url,callback=self.data_parse)
最后在解析函數(shù)中提取需要的數(shù)據(jù):
for job_item in jsonObject['engine_search_result']: items = JobprojectItem() items[’job_name’] = job_item[’job_name’] items[’company_name’] = job_item['company_name'] # 發(fā)布時(shí)間 items[’Releasetime’] = job_item[’issuedate’] items[’salary’] = job_item[’providesalary_text’] items[’site’] = job_item[’workarea_text’] .......
相關(guān)的細(xì)節(jié)部分需要自己調(diào)整,完整代碼在 GitHub 中。
數(shù)據(jù)爬取部分解決后,需要到scrapy項(xiàng)目中的pipline文件保存;
class SeemeispiderPipeline(object): def process_item(self, item, spider): item.save() return item
記得在setting文件中取消掉pipline的注釋
設(shè)置數(shù)據(jù)庫(kù):
Django配置數(shù)據(jù)庫(kù)有兩種方法:
方法一:直接在settings.py文件中添加數(shù)據(jù)庫(kù)配置信息(個(gè)人使用的)
DATABASES = { # 方法一 ’default’: { ’ENGINE’: ’django.db.backends.mysql’, # 數(shù)據(jù)庫(kù)引擎 ’NAME’: ’mysite’, # 數(shù)據(jù)庫(kù)名稱(chēng) ’USER’: ’root’, # 數(shù)據(jù)庫(kù)登錄用戶名 ’PASSWORD’: ’123’,# 密碼 ’HOST’: ’127.0.0.1’,# 數(shù)據(jù)庫(kù)主機(jī)IP,如保持默認(rèn),則為127.0.0.1 ’PORT’: 3306, # 數(shù)據(jù)庫(kù)端口號(hào),如保持默認(rèn),則為3306 }}
方法二:將數(shù)據(jù)庫(kù)配置信息存到一個(gè)文件中,在settings.py文件中將其引入。
新建數(shù)據(jù)庫(kù)配置文件my.cnf(名字隨意選擇)
[client]database = bloguser = blogpassword = bloghost =127.0.0.1port = 3306default-character-set = utf8
在settings.py文件中引入my.cnf文件
DATABASES = { # 方法二: ’default’: { ’ENGINE’: ’django.db.backends.mysql’, ’OPTIONS’: { ’read_default_file’: ’utils/dbs/my.cnf’, }, }}
啟用Django與mysql的連接
在生產(chǎn)環(huán)境中安裝pymysql 并且需要在settings.py文件所在包中的 __init__.py 中導(dǎo)入pymysql

import pymysqlpymysql.install_as_MySQLdb()
對(duì)應(yīng)前面的item,在spider中編寫(xiě)時(shí)按照model設(shè)置的即可;;
from django.db import models# Create your models here.#定義app51的數(shù)據(jù)模型class app51data(models.Model): #發(fā)布時(shí)間,長(zhǎng)度20 Releasetime = models.CharField(max_length=20) #職位名,長(zhǎng)度50 job_name =models.CharField(max_length=50) #薪水 salary = models.CharField(max_length=20) #工作地點(diǎn) site = models.CharField(max_length=50) #學(xué)歷水平 education = models.CharField(max_length=20) #公司名稱(chēng) company_name = models.CharField(max_length=50) #工作經(jīng)驗(yàn) Workexperience = models.CharField(max_length=20) #指定表名 class Meta: db_table = ’jobsql51’ def __str__(self): return self.job_name
當(dāng)指定完表名后,在DBMS中只需要?jiǎng)?chuàng)建對(duì)應(yīng)的數(shù)據(jù)庫(kù)即可,表名自動(dòng)創(chuàng)建
每次修改數(shù)據(jù)庫(kù)都要進(jìn)行以下命令:
python manage.py makemigrationspython manage.py migrate
到此mysql數(shù)據(jù)庫(kù)配置完成
配置數(shù)據(jù)庫(kù)時(shí)遇到的錯(cuò)誤:
Django啟動(dòng)報(bào)錯(cuò):AttributeError: ’str’ object has no attribute ’decode’
解決方法:
找到Django安裝目錄
G:envdjango_jobLibsite-packagesdjangodbbackendsmysqloperations.py
編輯operations.py;
將146行的decode修改成encode
def last_executed_query(self, cursor, sql, params): # With MySQLdb, cursor objects have an (undocumented) '_executed' # attribute where the exact query sent to the database is saved. # See MySQLdb/cursors.py in the source distribution. query = getattr(cursor, ’_executed’, None) if query is not None: #query = query.decode(errors=’replace’) uery = query.encode(errors=’replace’) return query
django配置:
關(guān)于django的基礎(chǔ)配置,如路由,app的注冊(cè)等基礎(chǔ)用法,暫時(shí)不過(guò)多說(shuō)明;
以下主要關(guān)于APP中視圖的配置,生成json;
from django.shortcuts import renderfrom django.http import HttpResponse# Create your views here.#引入數(shù)據(jù)from .models import app51dataimport jsondef index(request): # return HttpResponse('hello world') # return render(request,’index.html’) #獲取所有的對(duì)象,轉(zhuǎn)換成json格式 data =app51data.objects.all() list3 = [] i = 1 for var in data: data = {} data[’id’] = i data[’Releasetime’] = var.Releasetime data[’job_name’] = var.job_name data[’salary’] = var.salary data[’site’] = var.site data[’education’] = var.education data[’company_name’] = var.company_name data[’Workexperience’] = var.Workexperience list3.append(data) i += 1 # a = json.dumps(data) # b = json.dumps(list2) # 將集合或字典轉(zhuǎn)換成json 對(duì)象 c = json.dumps(list3) return HttpResponse(c)
實(shí)現(xiàn)效果:
完整代碼在 GitHub 中,希望隨手star,感謝!
到此這篇關(guān)于Django-Scrapy生成后端json接口的方法示例的文章就介紹到這了,更多相關(guān)Django Scrapy生成json接口內(nèi)容請(qǐng)搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. 概述IE和SQL2k開(kāi)發(fā)一個(gè)XML聊天程序2. XML入門(mén)精解之結(jié)構(gòu)與語(yǔ)法3. XML解析錯(cuò)誤:未組織好 的解決辦法4. CSS3實(shí)例分享之多重背景的實(shí)現(xiàn)(Multiple backgrounds)5. 利用CSS3新特性創(chuàng)建透明邊框三角6. XML入門(mén)的常見(jiàn)問(wèn)題(一)7. HTML5 Canvas繪制圖形從入門(mén)到精通8. CSS Hack大全-教你如何區(qū)分出IE6-IE10、FireFox、Chrome、Opera9. HTML DOM setInterval和clearInterval方法案例詳解10. XML入門(mén)的常見(jiàn)問(wèn)題(二)
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備