文章列表
-
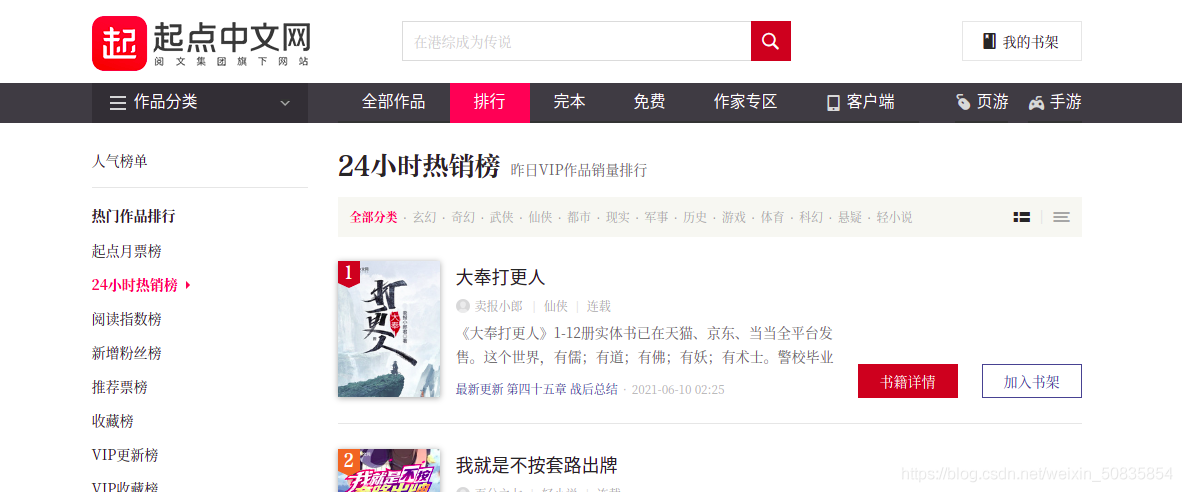
- Python scrapy爬取起點中文網小說榜單
- 一、項目需求爬取排行榜小說的作者,書名,分類以及完結或連載二、項目分析目標url:“https://www.qidian.com/rank/hotsales?style=1&page=1”通過控制臺搜索發現相應信息均存在于html靜態網頁中,所以此次爬蟲難度較低。通過控制臺觀察發現,...
- 日期:2022-06-16
- 瀏覽:10
-
- Django結合使用Scrapy爬取數據入庫的方法示例
- 在django項目根目錄位置創建scrapy項目,django_12是django項目,ABCkg是scrapy爬蟲項目,app1是django的子應用2.在Scrapy的settings.py中加入以下代碼import osimport syssys.path.append(os.path.dir...
- 日期:2024-09-11
- 瀏覽:7
- 標簽: Django
-
- Python爬蟲實例——scrapy框架爬取拉勾網招聘信息
- 本文實例為爬取拉勾網上的python相關的職位信息, 這些信息在職位詳情頁上, 如職位名, 薪資, 公司名等等.分析思路分析查詢結果頁在拉勾網搜索框中搜索’python’關鍵字, 在瀏覽器地址欄可以看到搜索結果頁的url為: ’https://www.lagou.com/jobs/list_pyth...
- 日期:2022-07-17
- 瀏覽:139
-
- 一文讀懂python Scrapy爬蟲框架
- Scrapy是什么?先看官網上的說明,http://scrapy-chs.readthedocs.io/zh_CN/latest/intro/overview.htmlScrapy是一個為了爬取網站數據,提取結構性數據而編寫的應用框架。可以應用在包括數據挖掘,信息處理或存儲歷史數據等一系列的程序中。...
- 日期:2022-06-27
- 瀏覽:108

-
- Python爬蟲基礎之初次使用scrapy爬蟲實例
- 項目需求在專門供爬蟲初學者訓練爬蟲技術的網站(http://quotes.toscrape.com)上爬取名言警句。創建項目在開始爬取之前,必須創建一個新的Scrapy項目。進入您打算存儲代碼的目錄中,運行下列命令:(base) λ scrapy startproject quotesNew scr...
- 日期:2022-06-15
- 瀏覽:130
-
- python scrapy簡單模擬登錄的代碼分析
- 1、requests模塊。直接攜帶cookies請求頁面。找到url,發送post請求存儲cookie。2、selenium(瀏覽器自動處理cookie)。找到相應的input標簽,輸入文本,點擊登錄。3、scrapy直接帶cookies。找到url,發送post請求存儲cookie。# -*- c...
- 日期:2022-06-14
- 瀏覽:143

-
- Django-Scrapy生成后端json接口的方法示例
- 網上的關于django-scrapy的介紹比較少,該博客只在本人查資料的過程中學習的,如果不對之處,希望指出改正;以后的博客可能不會再出關于django相關的點;人心太浮躁,個人深度不夠,只學習了一些皮毛,后面博客只求精,不求多;希望能堅持下來。加油!學習點: 實現效果 django與scrap...
- 日期:2024-05-27
- 瀏覽:138
- 標簽: JavaScript

-
- Python Scrapy多頁數據爬取實現過程解析
- 1.先指定通用模板url = ’https://www.qiushibaike.com/text/page/%d/’#通用的url模板pageNum = 12.對parse方法遞歸處理parse第一次調用表示的是用來解析第一頁對應頁面中的數據對后面的頁碼的數據要進行手動發送if self.pageN...
- 日期:2022-07-21
- 瀏覽:195

-
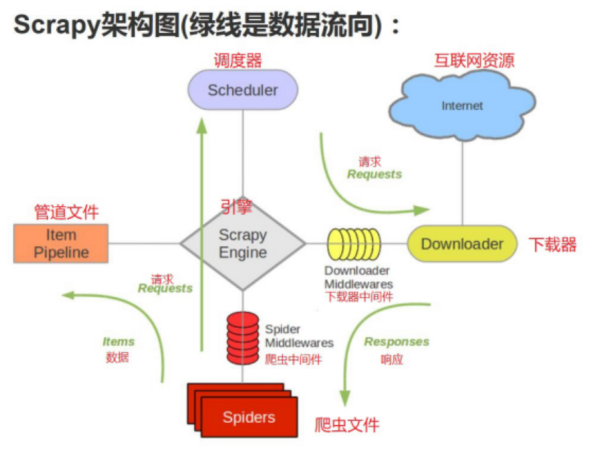
- python Scrapy框架原理解析
- Python 爬蟲包含兩個重要的部分:正則表達式和Scrapy框架的運用, 正則表達式對于所有語言都是通用的,網絡上可以找到各種資源。如下是手繪Scrapy框架原理圖,幫助理解如下是一段運用Scrapy創建的spider:使用了內置的crawl模板,以利用Scrapy庫的CrawlSpider。相對...
- 日期:2022-06-30
- 瀏覽:116
-
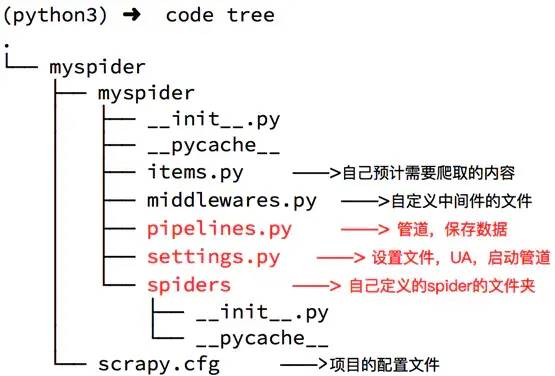
- Python爬蟲基礎之簡單說一下scrapy的框架結構
- scrapy 框架結構思考 scrapy 為什么是框架而不是庫? scrapy是如何工作的?項目結構在開始爬取之前,必須創建一個新的Scrapy項目。進入您打算存儲代碼的目錄中,運行下列命令:注意:創建項目時,會在當前目錄下新建爬蟲項目的目錄。這些文件分別是: sc...
- 日期:2022-06-15
- 瀏覽:127
排行榜

 網公網安備
網公網安備